객체 검출(Detection)
객체 검출은 이미지 내에 존재하는 객체와 위치를 검출하는 모델입니다.
데이터 업로드 하기
먼저, 생성한 프로젝트에서, Vision-ML에 접속합니다.
Vision-ML 화면에서, Add new Item 버튼을 클릭하거나, 우측의 ![]() 를 클릭합니다.
를 클릭합니다.
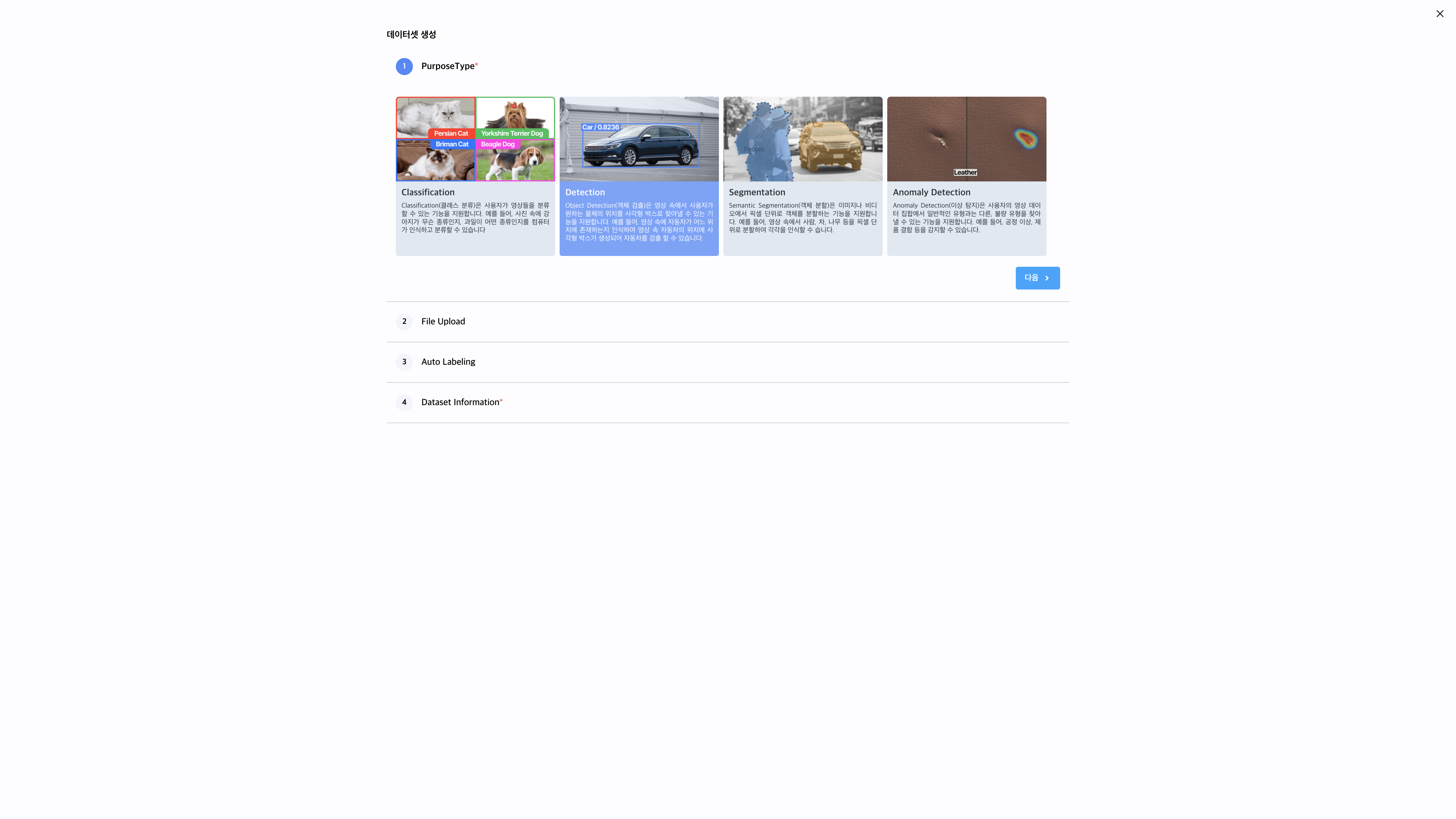
데이터셋 생성 화면에서, Purpose Type을 detection으로 선택한 후 다음 버튼을 클릭합니다.
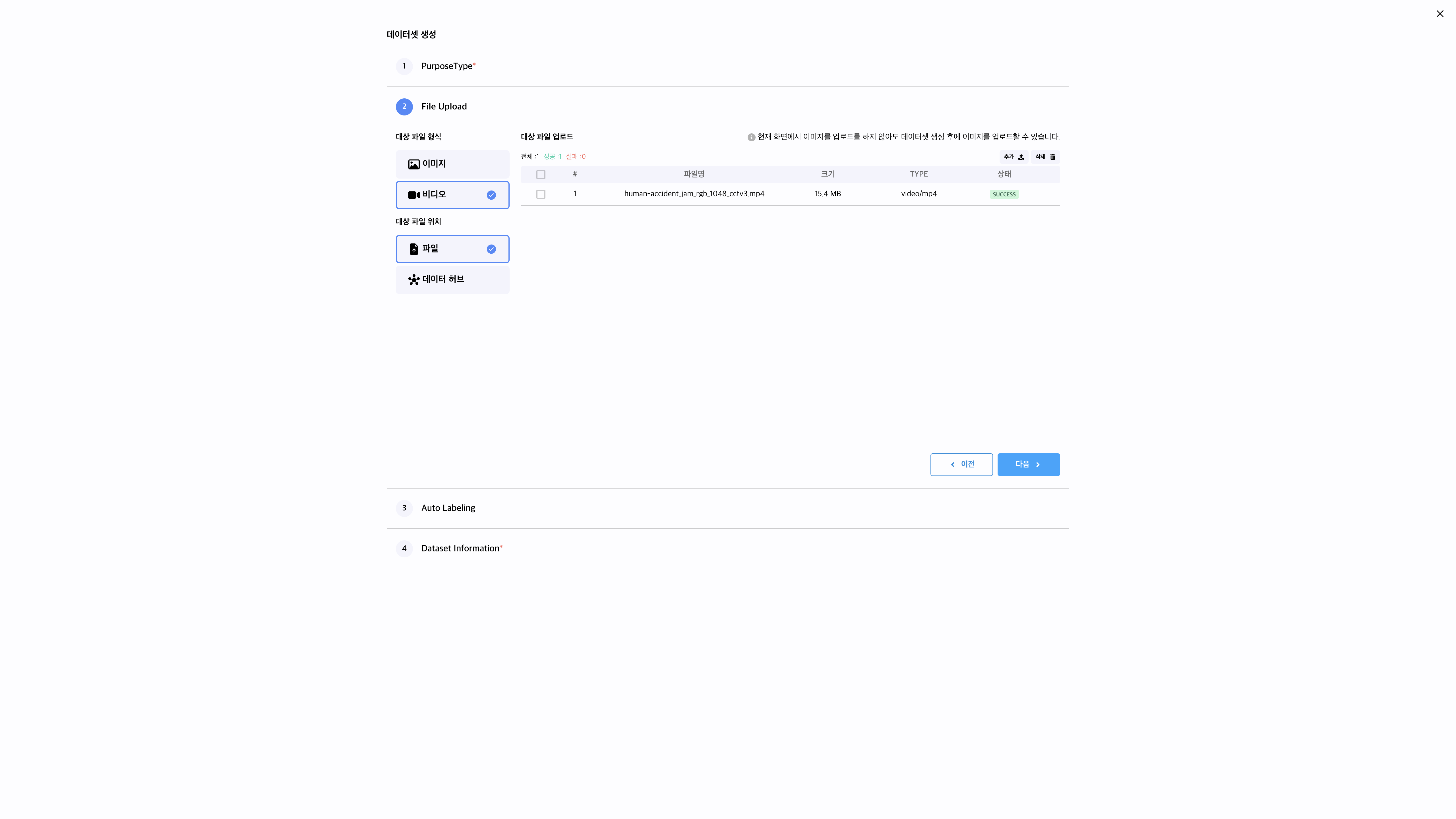
파일 업로드 화면에서, 왼쪽의 대상파일 형식을 이미지에서 비디오로 변경한 후 파일을 업로드합니다.
기존 1차 학습된 인공지능 모델이 있거나, 기본 제공 모델이 존재하는 경우, 해당 모델을 이용하여 Auto-Labeling을 진행할 수 있습니다.
파일이 정상적으로 업로드 된 것을 확인하였으면, 다음 버튼을 클릭합니다.
dataset information 화면에서, 데이터셋 이름, 데이터셋 설명을 입력합니다.
입력이 완료되면, 저장 버튼을 클릭하여 데이터셋을 생성합니다. 정상적으로 생성이 완료 된 경우 Vision-ML 화면에서 생성된 데이터셋 카드를 확인 할 수 있습니다.
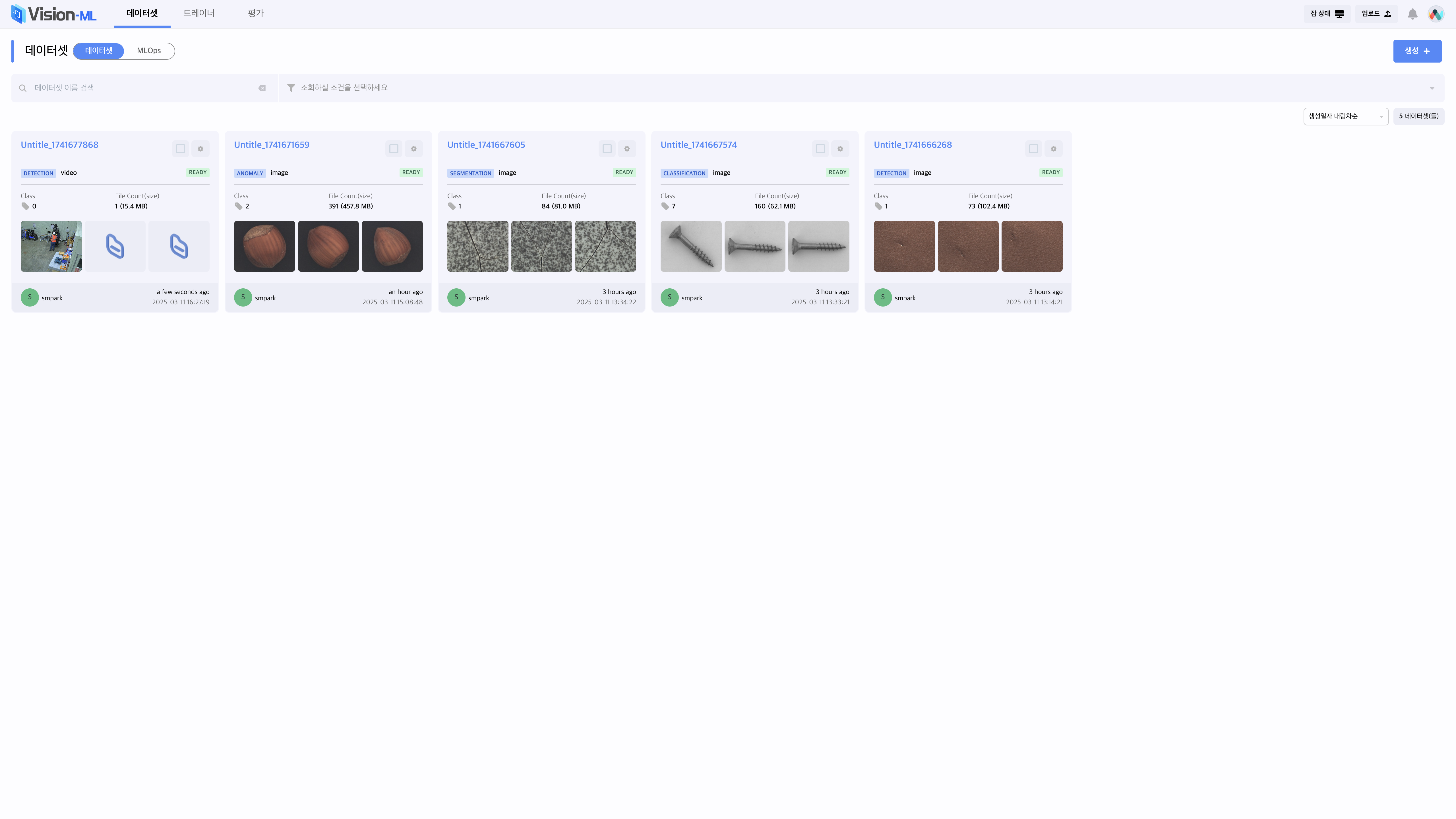
생성 된 데이터셋을 클릭하면, 라벨링 화면으로 이동합니다.
비디오 라벨링 역시 이미지 라벨링에서 지원하는 모든 기능을 동일하게 사용할 수 있습니다.
비디오 라벨링 화면에서는 비디오 프레임을 확인할 수 있으며, 프레임 단위로 라벨링을 진행할 수 있습니다.
또한, 비디오 라벨링에서는 객체 추적 기반의 Tracker를 사용하여 라벨링 할 수 있습니다.
Tracker 기능을 사용하기 위해서는 화면 좌측의 Tracker 버튼을(단축키 4) 클릭합니다.
라벨링 화면 하단의 Tracker 알고리즘을 선택하고, 사각형 박스를 그립니다. 이후, 찾을 프레임의 수를 입력하면 현재 프레임에서부터 찾을 프레임의 수만큼 추적을 진행합니다.
라벨링이 종료되면 저장 버튼 클릭 후 라벨링을 완료 합니다.