Training
데이터의 특징 분석, 편집이 완료되면 해당 데이터로 모델을 학습할 수 있습니다.
실험실의 두 번째 탭인 학습으로 이동하면 학습 가능한 모델의 목록과, 결과, 그리고 학습 모델의 상세 설정을 확인할 수 있습니다.
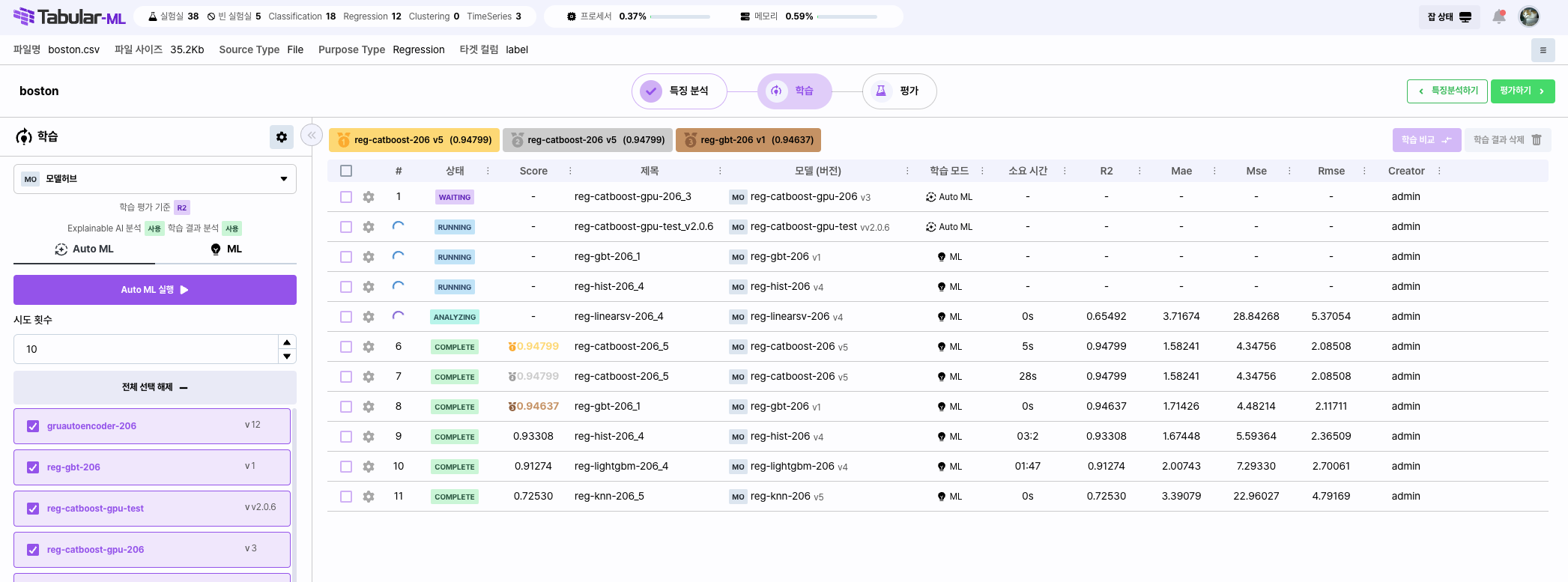
Model List
왼쪽 사이드바에는 학습 가능한 모델의 목록이 표시됩니다.
모델은 모델허브에 등록된 모델들이 표시되며 실행하고 싶은 모델을 사용자가 직접 선택해 학습할 수 있습니다.
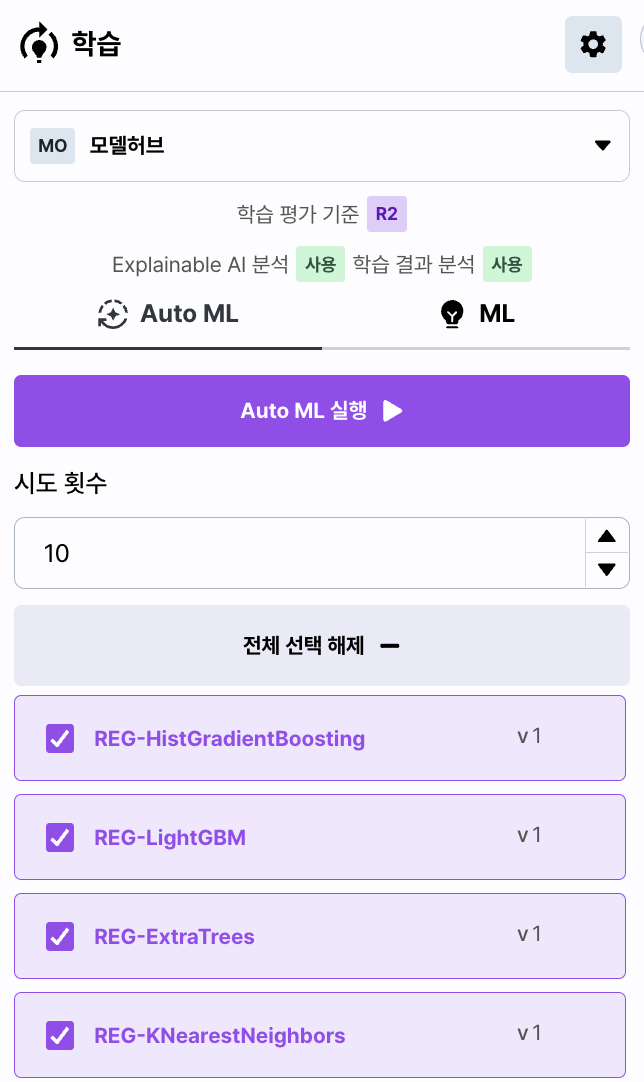
Setting
모델 패널 상단의 [설정] 버튼을 통해 모델 학습 시 필요한 전체적인 설정을 합니다.
다음과 같은 화면을 통해 학습하려는 모델의 평가 기준, 학습과 검증에 사용되는 데이터의 비율을 설정합니다.
또한 학습 시 그래프 생성 여부와 XAI 실행 여부를 함께 설정합니다.
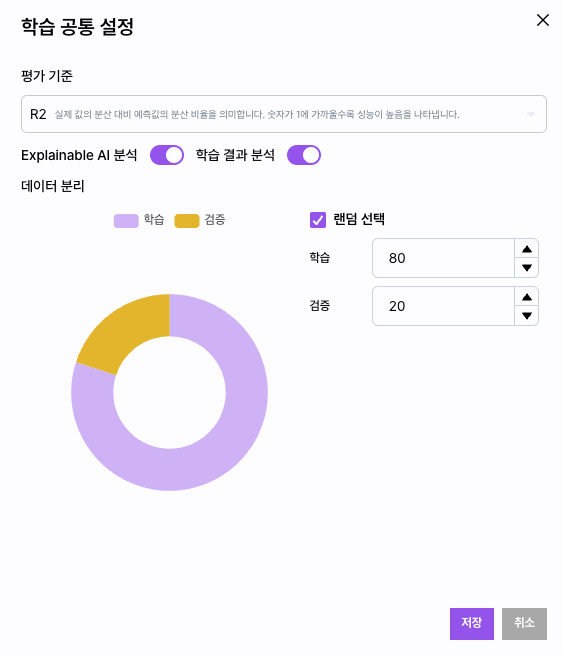
TRAIN
모델 패널 상단의 Auto ML 실행을 클릭하면 자동으로 데이터
셋에 대한 최적의 모델과 최적의 Hyper Parameter를 탐색합니다.
이 방법은 동시에 여러 모델의 학습과 테스트를 진행하기 때문에 데이터의 크기에 따라 많은 시간이 소요될 수 있습니다.
모델의 [플레이] 버튼을 선택하거나 Hyper Parameter 설정 창에서 [플레이] 버튼을 선택하면 학습이 시작됩니다.
학습이 종료되면 사용자가 설정한 Score에 따라 모델이 순서대로 정렬됩니다.
 |  |
|---|
TRAIN LOG
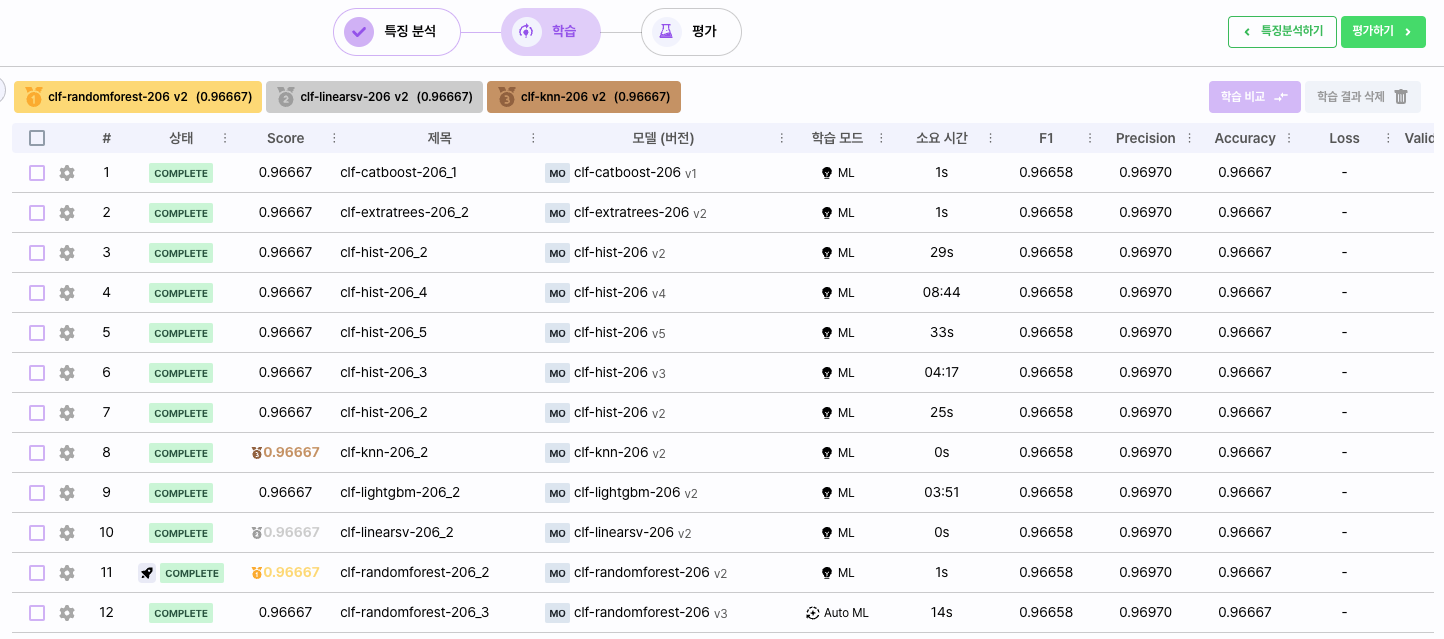
화면 중앙의 학습 결과 패널은 모델 학습의 결과와 히스토리를 표시합니다.
- 상태: 모델의 학습 상태를 표시합니다. Running, Fail, Complete으로 모델의 학습이 완료되었는지 확인할 수 있습니다.
- Score: 모델의 Score를 표시합니다. 기본적으로 Regression 목적의 경우 R2 스코어가, Classification 목적의 경우 Accuracy가 설정됩니다.
- 제목: 학습한 모델의 별칭이 표시됩니다.
- 모델: 학습한 모델의 이름이 표시됩니다.
- 학습모드: 모델의 학습 타입입니다 (AutoML/ML)
- 소요 시간: 모델이 학습하는데 소요된 시간입니다.
- 성능지표: 모델이 학습한 지표들이 평가됩니다. PurposeType에 따라 성능지표는 달라집니다.
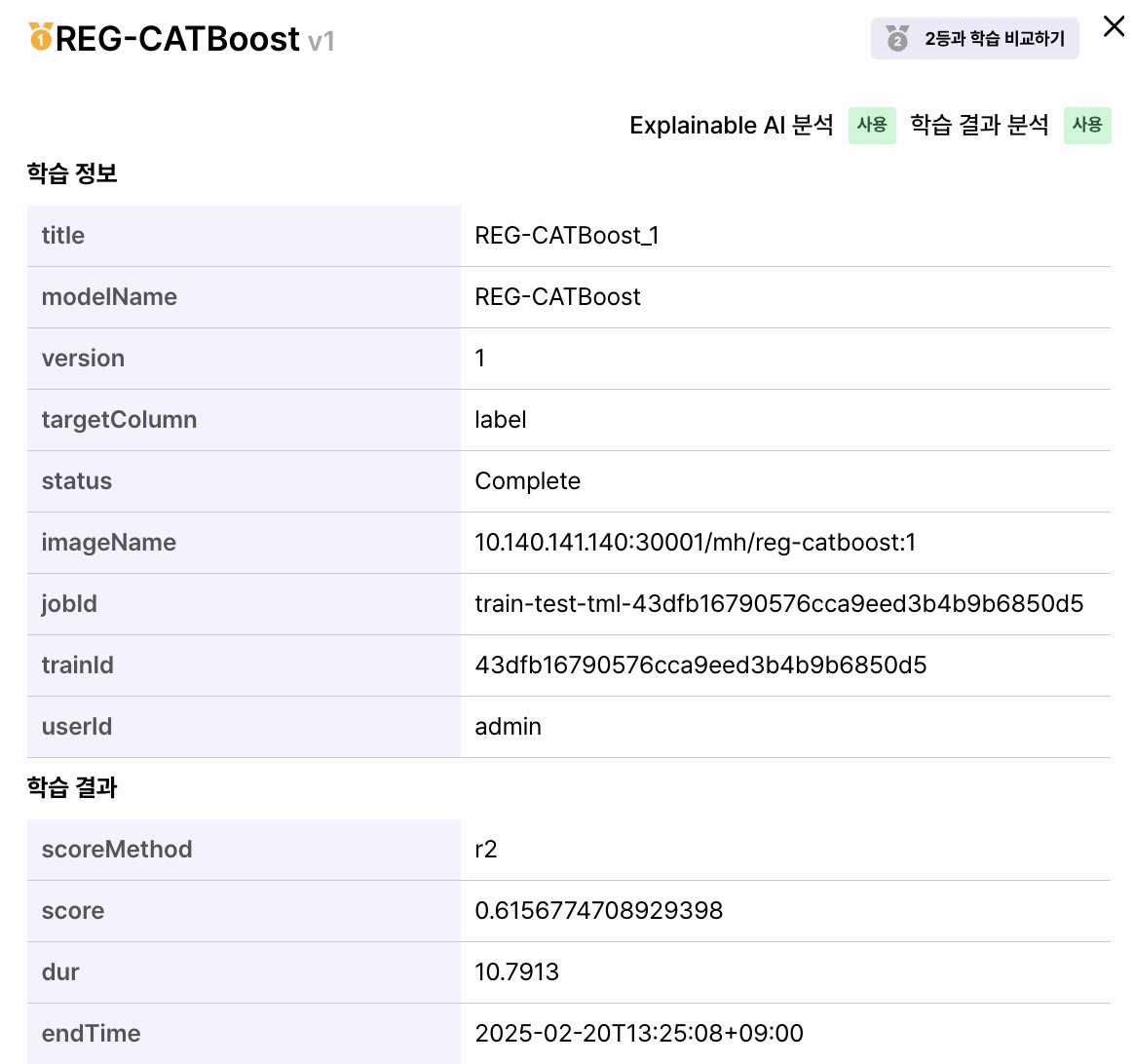
화면 오른쪽 패널 학습 결과 상세 영역은 학습 결과 패널에서 선택한 모델의 상세 정보를 표시합니다.
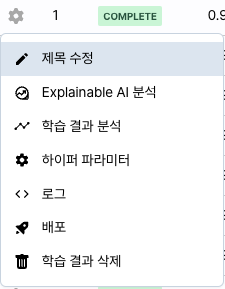
학습 리스트의 가장 좌측의 ![]() 버튼을 누르면 분석 가능한 기능의 모음이 표시됩니다.
버튼을 누르면 분석 가능한 기능의 모음이 표시됩니다.
모델의 결과 확인이나 모델 배포, 삭제 등의 기능을 사용할 수 있습니다.
Explainable AI
[ExplainAble AI 분석] 버튼을 클릭하면 해당 모델 기반의 영향도, 인자 설명의 분석 자료를 확인할 수 있습니다.
Explainable AI는 Feature Effect와 Prediction Explanation로 구성됩니다.
Feature Effect
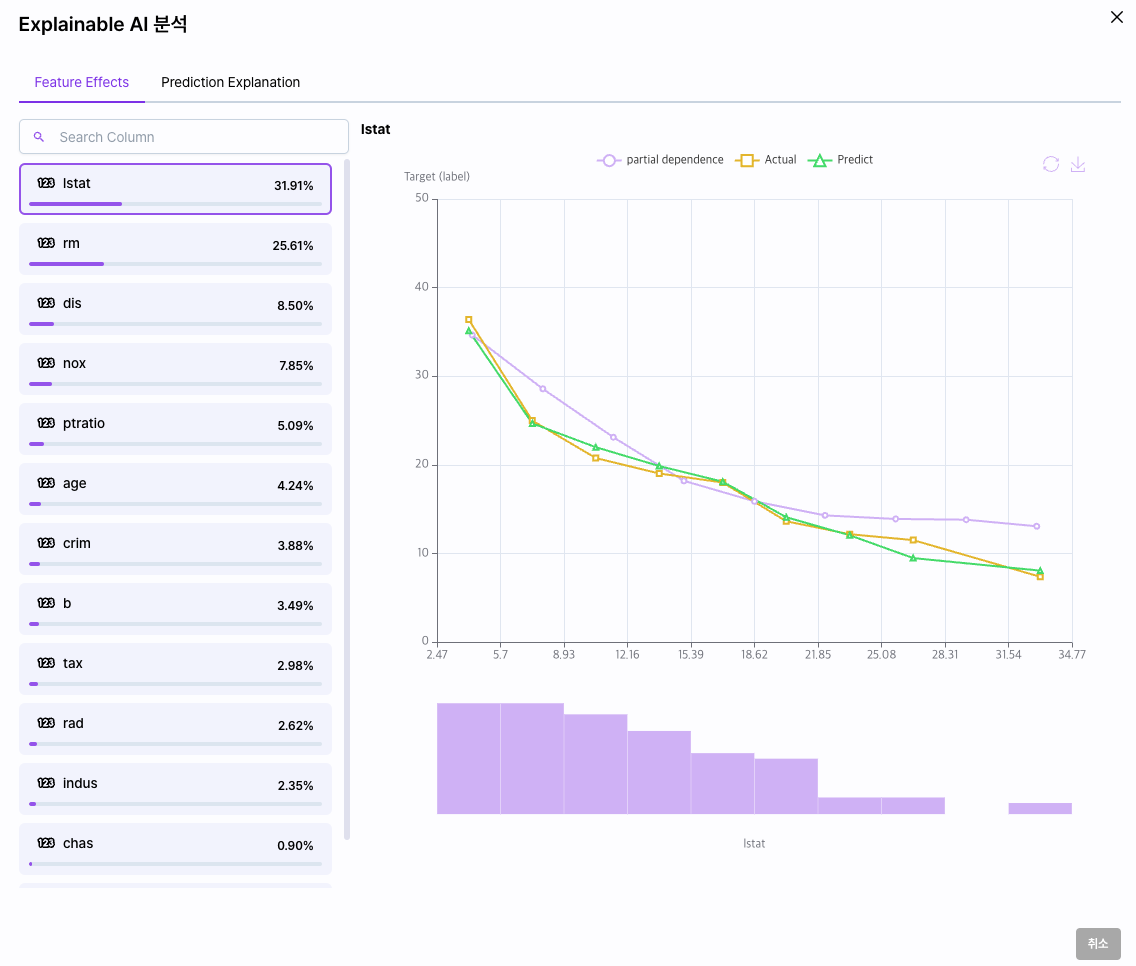
왼쪽 열은 해당 모델을 학습할 때 모델이 주요하게 참고한 변수들과 각 영향도를 표시합니다.
변수를 선택하면 우측에 영향도 차트가 출력됩니다.
![]()
영향도는 의존도, 실제값, 예측값 그리고 히스토그램으로 표현됩니다.
- 의존도: 해당 컬럼이 학습에 포함되지 않았다면 모델이 예측했을 값을 표시
- 실제값: 모델 학습 시 테스트셋에 포함된 실제 변수의 값
- 예측값: 학습 왼료된 모델이 실제로 예측한 값
- 히스토그램: 선택한 변수의 분포
일반적으로 노란선(실제값)과 파란선(예측값)이 비례하거나 일치할수록 모델에 영향력이 큽니다.
실제값과 예측값이 가까울 때 의존도가 반비례하거나 차트상 동떨어져 있다면 해당 변수가 모델에 주는 영향도가 큰 것을 알 수 있습니다.
Prediction Explanation
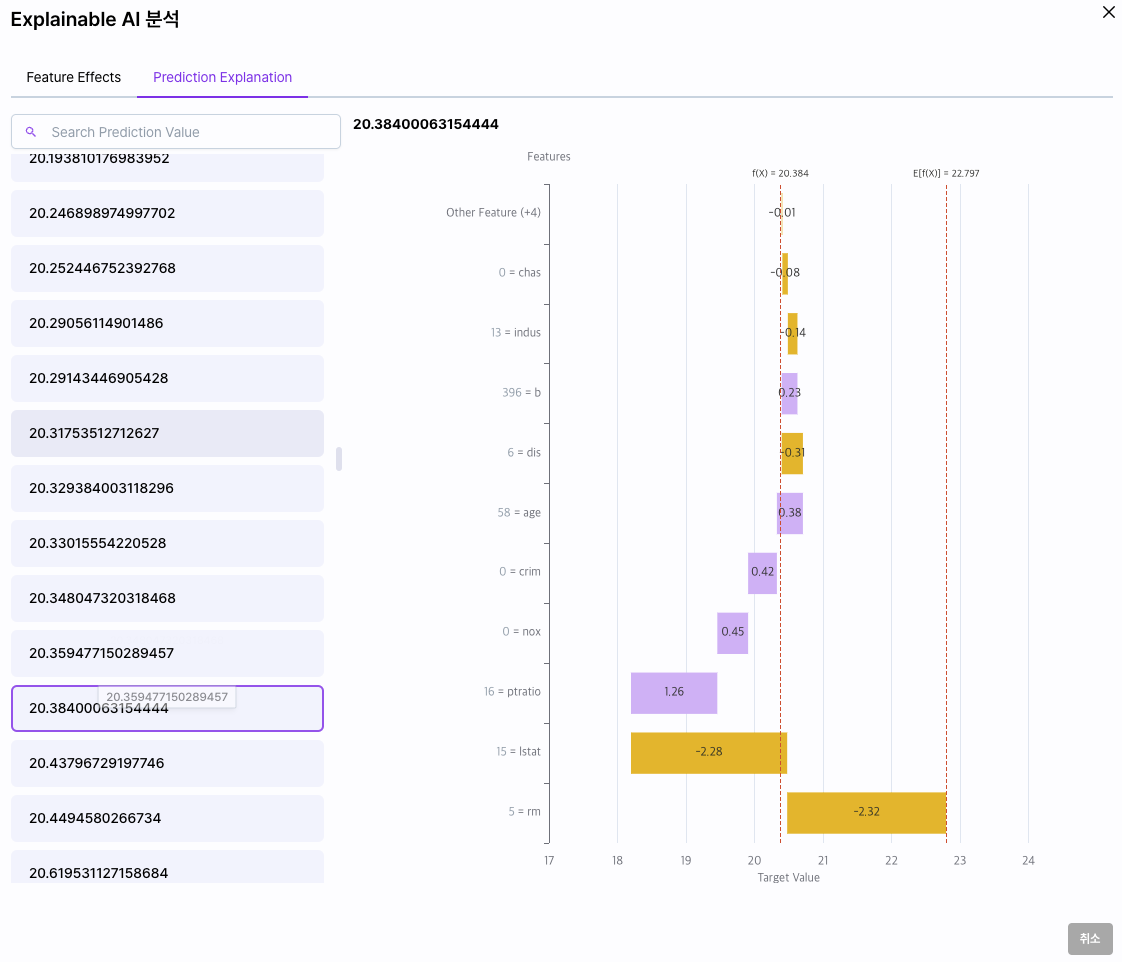
왼쪽 열은 해당 모델을 학습할 때 사용한 테스트셋의 예측 결과를 표시 합니다. 리스트에서 하나의 예측 값을 선택하면 오른쪽에 해당 예측에 기여한 컬럼들의 정보를 확인할 수 있습니다.
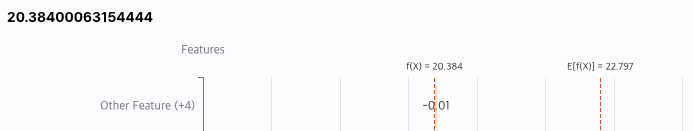
차트의 상단에 표시된 수치는 예측 값입니다. 차트에 표시된 두 개의 기준선은 각각 E[f(X)] 그리고 f(X)입니다.
- E[f(X)]: 예측의 기댓값으로 해당 예측의 예측 결과로 기대한 값입니다.
- f(x): 실제 예측 값으로 차트를 보면 두개의 기준선 사이에 여러 변수들이 +, -로 영향을 줍니다.
Prediction Explanation은 기대한 예측값과 실제 예측값 사이에 각 변수들이 기여한 정도를 분석하는 기능입니다.
예측 범위에 따라 (예측 값이 낮거나, 높거나) 서로 다른 변수별 기여도를 확인할 수 있습니다.
이를 통해 특정 변수값의 크기에 따라 예측 결과가 높게 나올지, 낮게 나올지 등 예측 패턴별 주요 인자와 기여도를 확인할 수 있습니다.
Training Result
[학습 결과 분석] 버튼을 클릭하면 해당 모델의 학습 정보를 표시합니다.
PurposeType에 따라 다른 그래프가 학습 결과로 표시됩니다
-
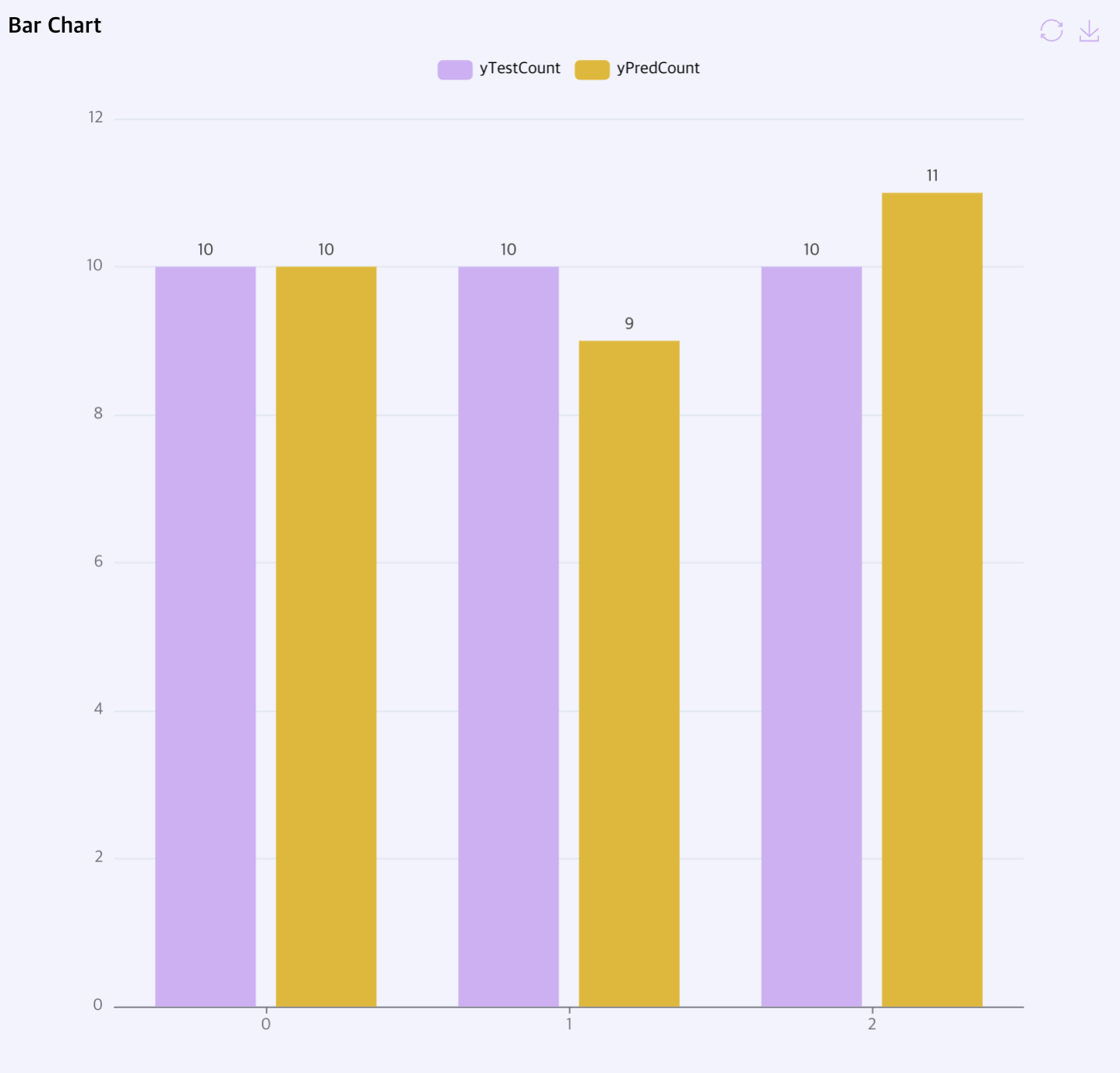
Bar Chart: 학습 / 검증셋으로 예측한 분류 결과를 표시합니다.
-
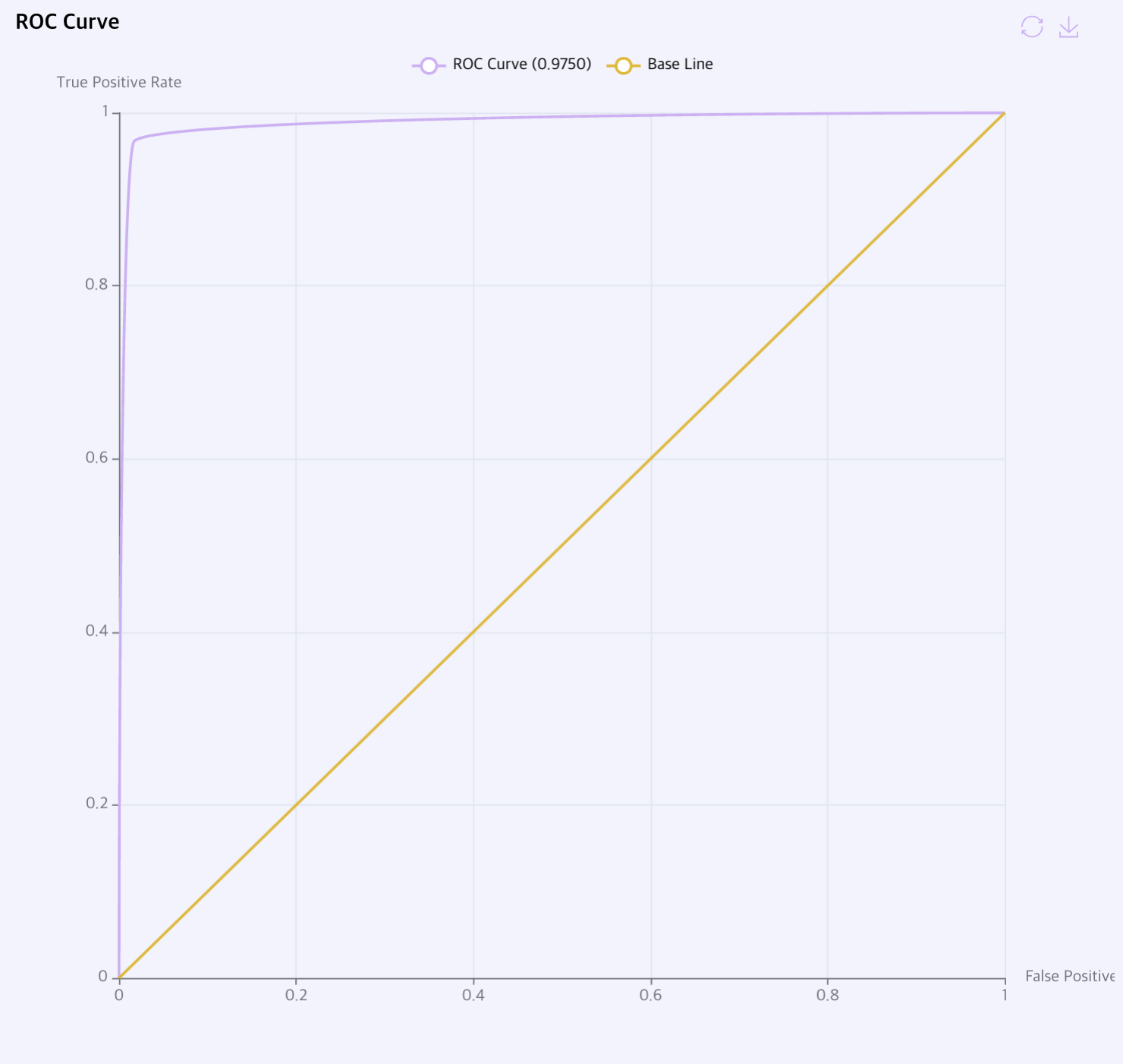
ROC Curve: 민감도 / 특이도로 구성된 학습 그래프를 표시합니다. 그래프의 기울기가 왼쪽 상단에 가까울수록 좋은 결과입니다.
-
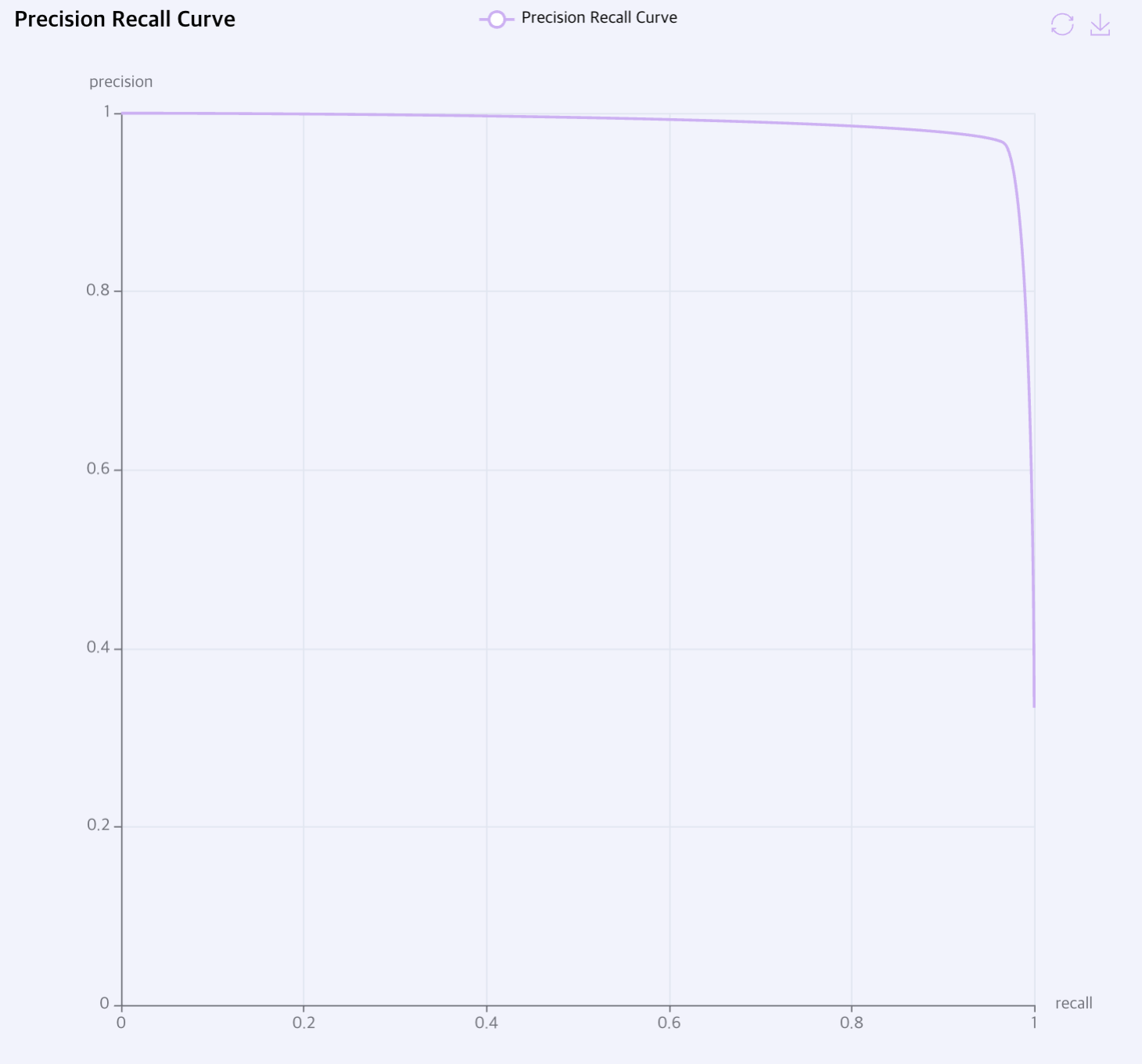
Precision Recall Curve: 정밀도(Precision)와 재현율(Recall)로 구성된 학습 그래프를 표시합니다. 기울기가 오른쪽 상단에 가까울수록 좋은 결과입니다.
-
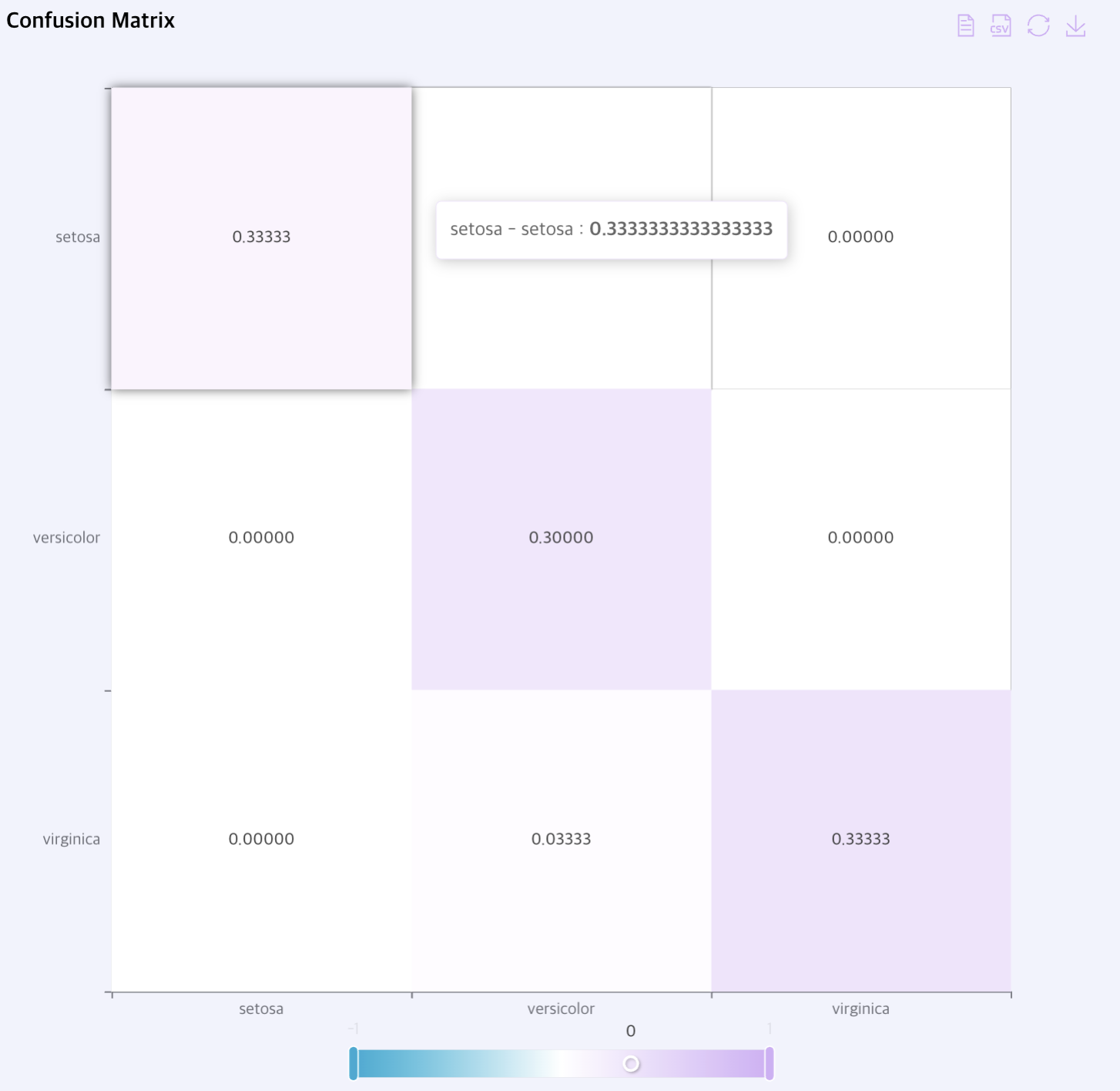
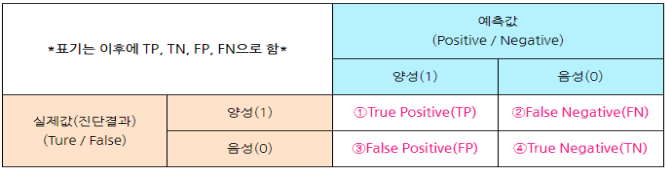
Confusion Matrix: TP, TN, FP, FN으로 구성된 표를 표시합니다.
-
Feature Importance: 모델이 학습할 때 가장 많은 영향을 준 컬럼 정보를 표시합니다.
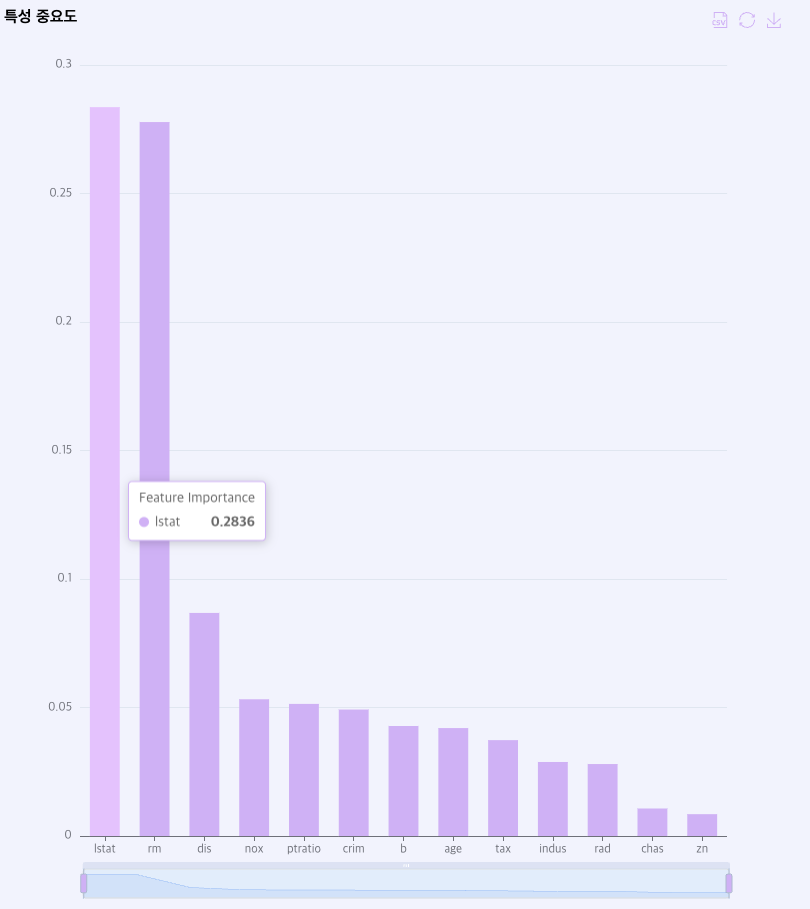
-
Reg Plot: 데이터의 분포와 데이터를 선형으로 표현하는 회귀선을 동시에 표현하는 그래프입니다.
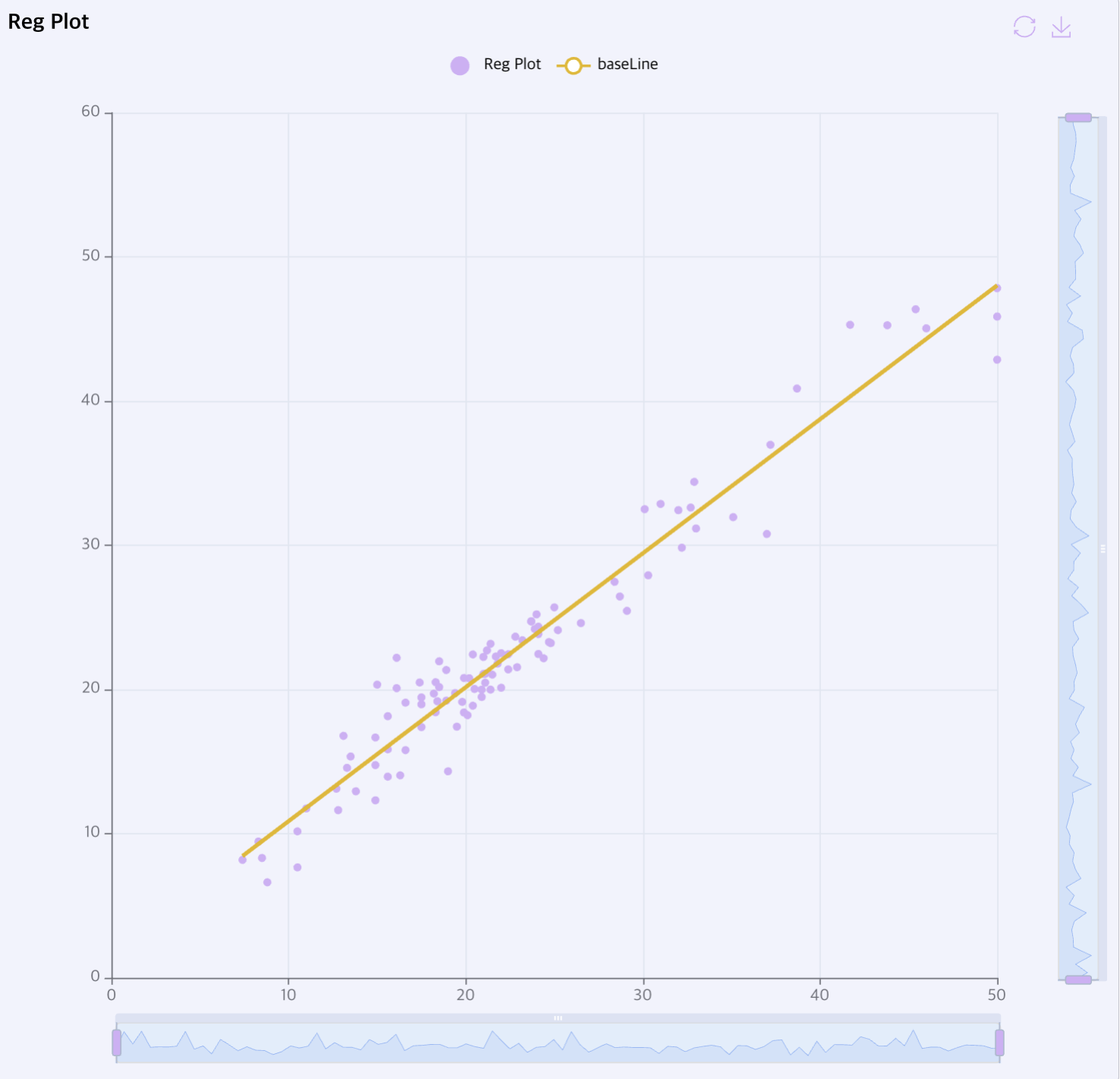
-
Distribution Plot: 예측한 값과 실제 정답값을 비교한 차트입니다.
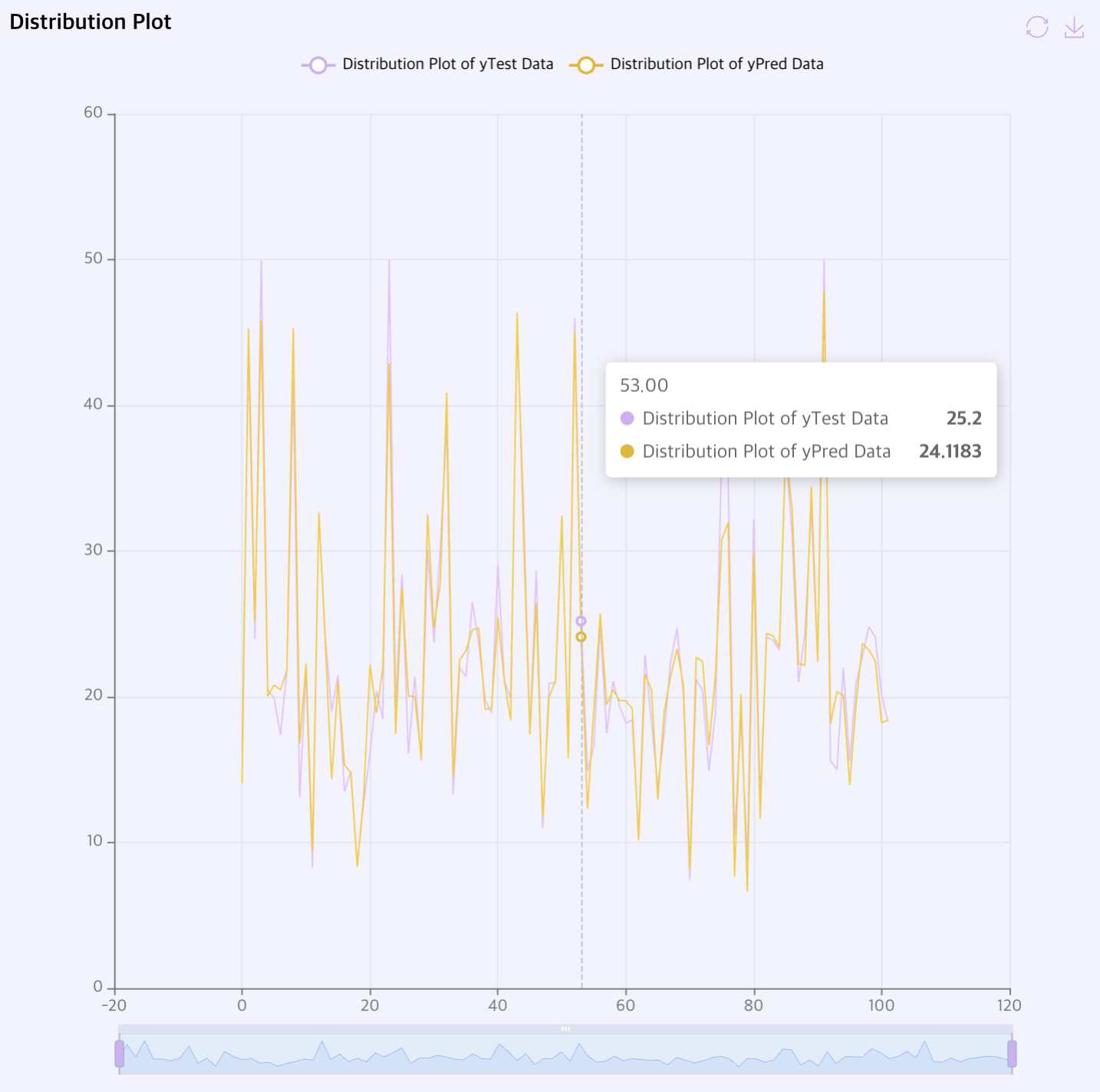
Hyper Parameter
모델 리스트 오른쪽에 있는 [하이퍼파라미터] 버튼을 클릭하면 해당 모델의 Hyper Parameter를 직접 설정할 수 있습니다.
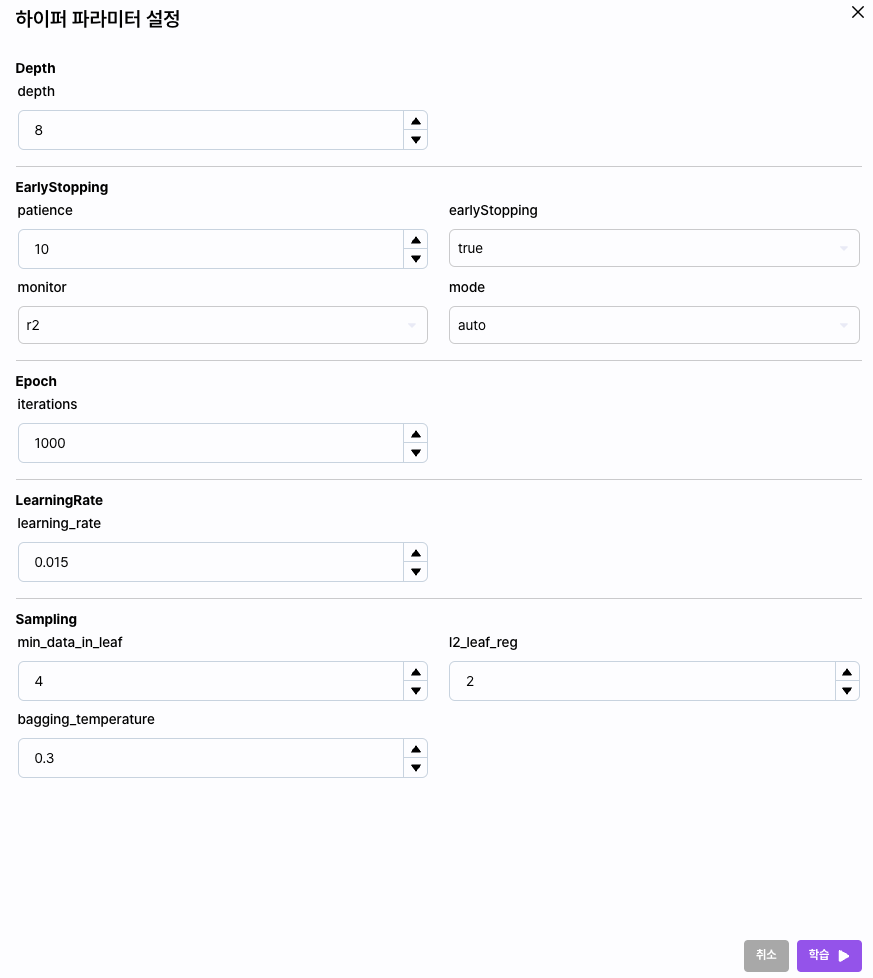
Hyper Parameter는 모델마다 가지고 있는 특정 설정값입니다. 해당 모델에 대한 특징이나 공식 문서를 참고해 값을 수정할 수 있습니다.
Model Log
[로그] 버튼을 클릭하면 모델의 학습 로그를 확인할 수 있습니다.
Deployment
[배포] 버튼을 클릭하면 모델허브에 해당 모델을 배포합니다.
Delete Model
[학습결과 삭제] 버튼을 클릭하면 해당 학습 결과를 삭제합니다.