Feature Engineering
데이터가 수집되고 [데이터셋 생성] 버튼을 클릭하면 TML 서비스가 자동으로 수집된 데이터의 기술 통계 자료를 분석합니다.
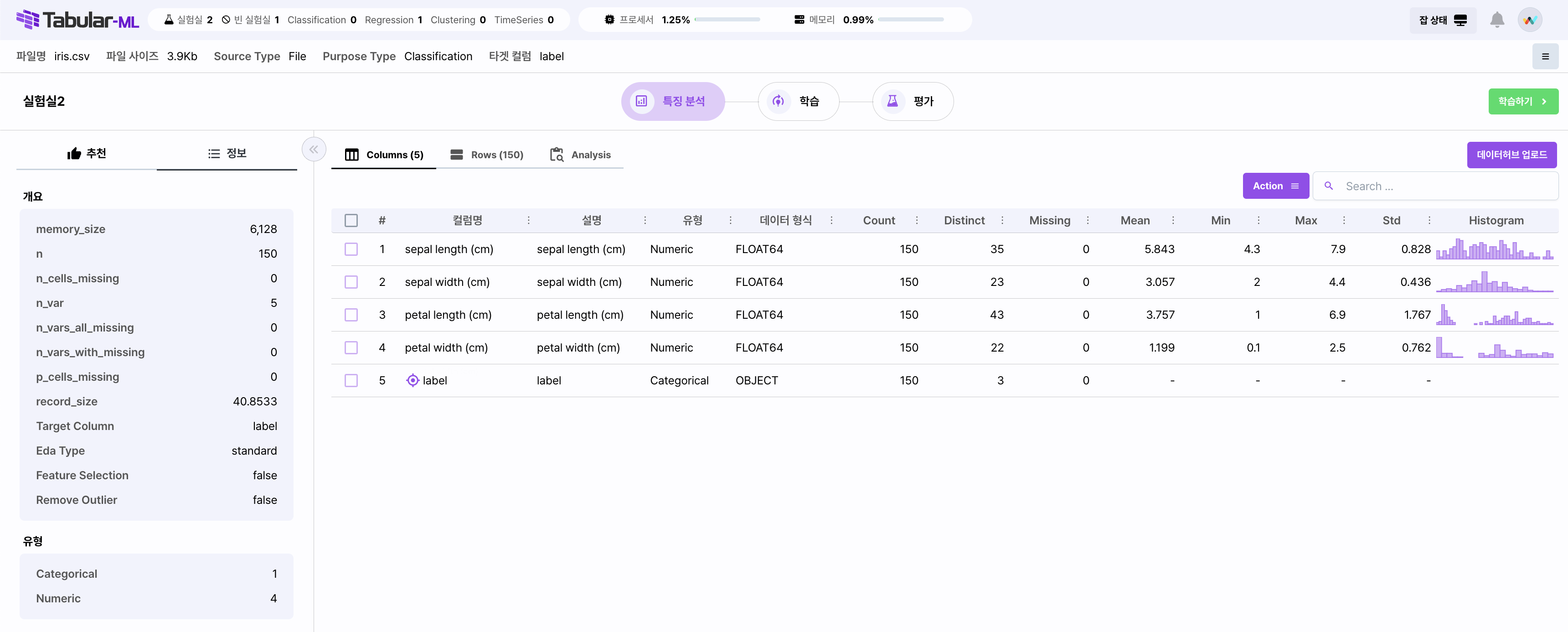
특징 분석 탭을 통해 자동으로 분석한 기술 통계 자료를 영역별로 확인할 수 있습니다.
| 필드명 | 설명 |
|---|---|
| 개요 | 데이터의 전반적인 정보를 표시합니다. |
| 유형 | 데이터를 구성하고 있는 컬럼들의 타입을 표시합니다. |
| 추천 | 데이터를 자동으로 분석해 전처리가 필요한 사항을 추천합니다. |
| 특징 분석 | Columns, Rows, Analysis 탭으로 구성되어 있습니다. - Columns: 컬럼 별 형식과 수, 최대 최소값과 같은 통계자료를 표시합니다. - Rows: 실제 Row 별 데이터를 조회할 수 있습니다. - Analysis: 데이터의 시각화 분석 자료를 제공합니다. |
| 오른쪽 사이드바 | 선택한 컬럼의 기술 통계 자료를 표시합니다. |
Column Alias
데이터셋의 컬럼명에 별칭을 설정합니다.
수집한 데이터셋의 컬럼명을 보여주고 컬럼 설명을 직접 작성하거나 파일을 업로드하여 컬럼 설명을 설정할 수 있습니다.
설명 파일 업로드
샘플 파일에서 comment 영역의 내용을 수정합니다. 수정된 파일을 업로드하고 적용 버튼을 누르면 컬럼 설명들이 일괄 적용됩니다.

컬럼 설명 직접 설정
수집한 데이터셋의 컬럼 설명을 일괄적으로 변경합니다. 컬럼 설명 패널의 [CSV] 아이콘을 누르면 샘플 파일을 다운로드 받을 수 있습니다. \

컬럼설명 [토글] 버튼을 통해 컬럼명 보기 / 컬럼 설명 보기로 전환 가능합니다. 컬럼 설명 보기로 전환된 경우 실험실 내에서 컬럼명으로 표시되는 부분이 컬럼 설명으로 변경되어 표시됩니다.
Data Overview
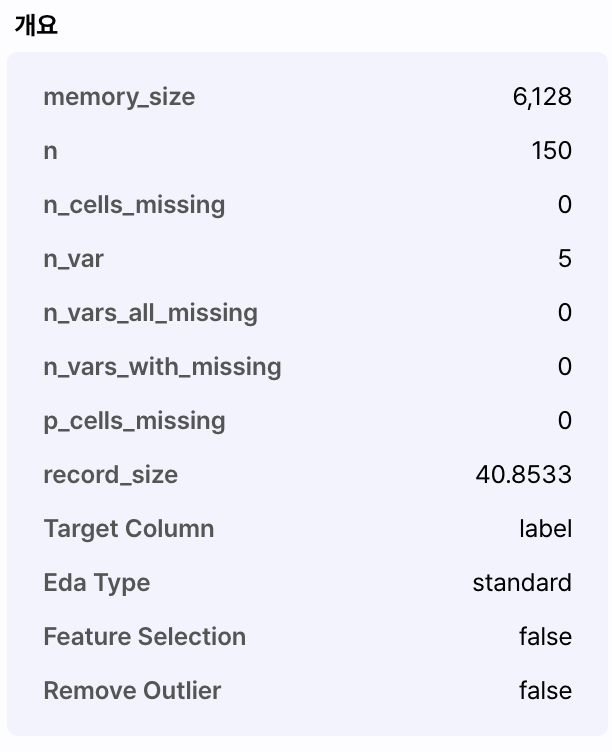
개요 화면에서 제공하는 정보는 다음과 같습니다.
| 필드명 | 설명 |
|---|---|
| Row | 데이터의 로우 수를 표시합니다. |
| Columns | 데이터의 컬럼 수를 표시합니다. |
| Memory size | 데이터의 크기를 표시합니다. 해당 데이터를 적재하면 메모리에 할당되는 크기입니다. |
| Record size | 메모리의 평균 레코드 사이즈를 표시합니다. |
| Missing cells | 데이터에 포합된 누락데이터의 수를 표시합니다. |
| Column with missing | 누락 데이터를 포함하고 있는 컬럼의 수를 표시합니다. |
| Missing Columns | 컬럼 전체가 누락데이터인 컬럼의 수를 표시합니다. |
| Missing cells(%) | 전체 데이터에서 누락된 셀의 분포를 표시합니다. |
| Target Column | 데이터가 예측하고자 하는 목표 컬럼명을 표시합니다. |
| Feature Selection | 자동화 기술 중 자동 특징 선택 기능을 적용했는지 여부를 표시합니다. |
| Remove Outlier | 자동화 기술 중 자동 아웃라이어 제거 기능을 적용했는지 여부를 표시합니다. |
Data Type
유형 화면에서는 데이터셋을 구성하고 있는 데이터의 유형 및 개수가 표시됩니다.

Categorical 데이터를 포함해 인공지능 학습을 진행할 때는 컬럼에 포함되어 있는 범주들이 유일한지 점검해야 합니다.
예를 들어 [사과, 바나나, 배]를 포함하고 있는 데이터셋으로 학습할 경우 [포도]는 예측할 수 없습니다.
따라서 해당 Categorical 데이터가 데이터셋 안에서 충분히 모든 범주를 포함하고 있는지 확인해야 합니다.
Data Recommandation
추천 화면은 TML 서비스가 자동으로 데이터셋에서 전처리가 필요한 컬럼과 처리 방법을 추천합니다.
추천 화면에서 제공하는 정보는 다음과 같습니다.
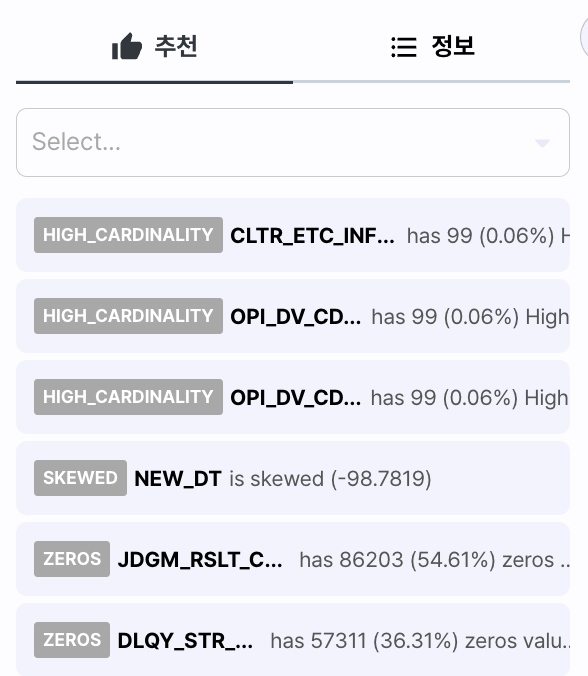
추천사항의 구성은 다음과 같습니다.
- 구분: 추천 사항
- 대상컬럼: 컬럼명
- 내용: 컬럼이 추천된 이유
추천 사항의 종류는 다음과 같습니다.
| 추천 사항 | 설명 |
|---|---|
| SKEWED | 데이터가 불균형하게 구성 |
| UNSUPPORTED | 지원하지 않는 데이터 |
| MISSING | 누락된 데이터가 포함되어 있음 |
| CONSTANT | 데이터가 단일값으로 구성 |
| ZEROS | 데이터가 0으로만 구성 |
| REJECTED | CONSTANT, ZEROS가 존재해 해당 컬럼을 사용 불가 |
| HIGH_CARDINALITY | 매우 드물거나, 고유한 값들로 이뤄진 컬럼 |
추천 사항을 참고하여 해당 컬럼을 제거할지, 별도의 전처리 기술을 적용할지 판단할 수 있습니다.
Data Characteristic
특징 분석 화면에서 컬럼을 선택하면 오른쪽 사이드바에 다음과 같은 정보가 표시됩니다.
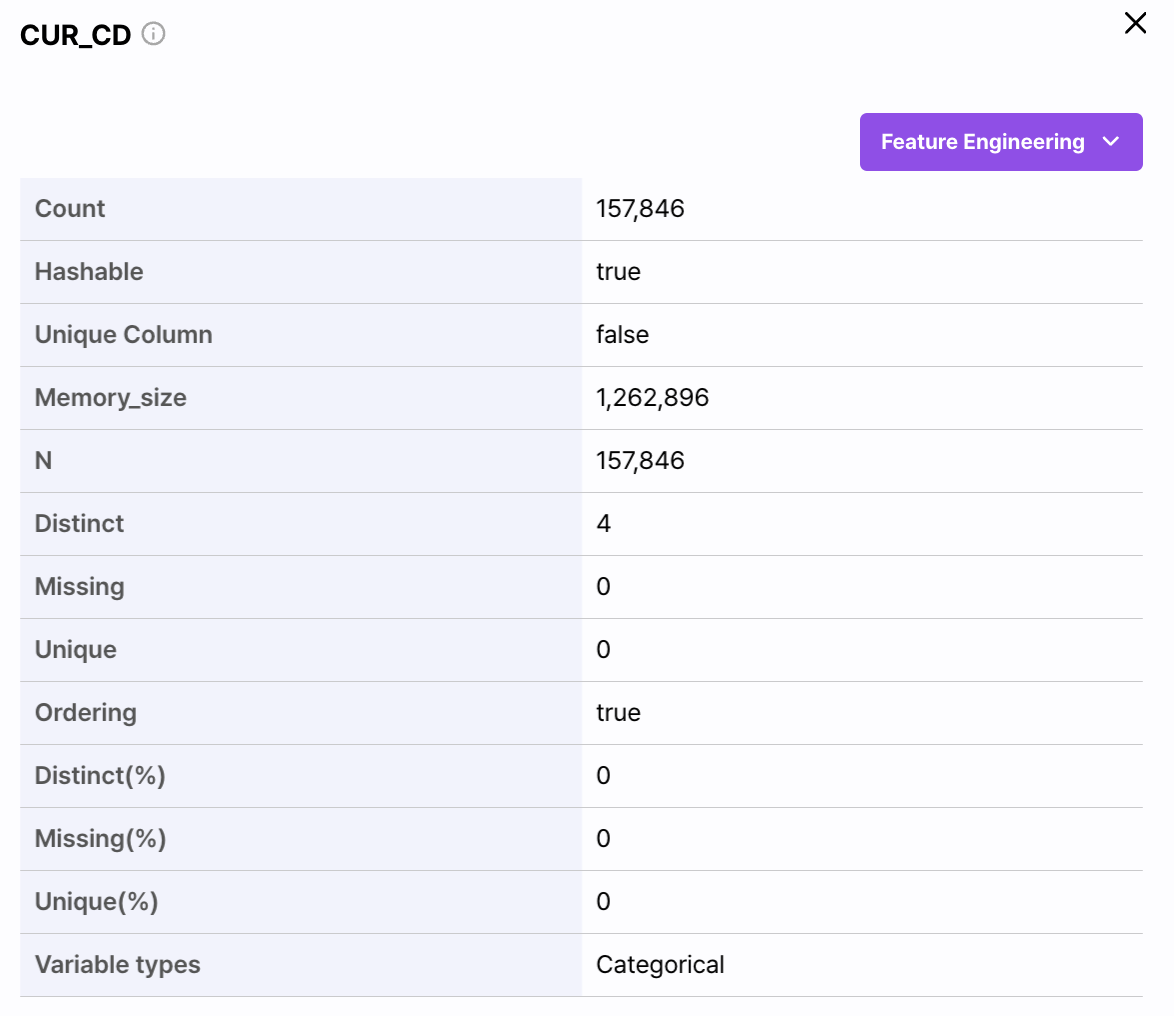
Categorical Type
Categorical 컬럼을 선택한 경우 다음의 정보를 제공합니다.
| 필드명 | 설명 |
|---|---|
| Distinct | 선택한 컬럼에서 중복되지 않은 로우의 수를 표시합니다. |
| Distinct(%) | 선택한 컬럼에서 전체 로우에 중복되지 않은 로우가 차지하는 비율을 표시합니다. |
| Unique Column | 선택한 컬럼의 데이터가 고유한지에 대한 여부를 표시합니다. |
| Unique | 누락된 값을 제외하고 고유한 값의 수를 표시합니다. |
| Unique (%) | 누락된 값을 제외하고 고유한 값의 비율을 표시합니다. |
| Variable Types | 데이터의 타입을 표시합니다. |
| Hashable | 선택한 데이터가 해쉬화 되어 있는지를 표시합니다. |
| Ordering | 선택한 데이터가 정렬되어 있는지를 표시합니다. |
| Missing | 해당 데이터에서 누락된 값의 수를 표시합니다. |
| N | 누락된 값을 포함해 전체 로우의 수를 표시합니다. |
| Missing(%) | 해당 컬럼에 있는 누락 데이터의 비율을 표시합니다. |
| Count | 해당 컬럼에서 누락 값을 제외한 데이터 수를 표시합니다. |
| Memory_size | 해당 컬럼이 차지하는 메모리 사이즈를 표시합니다. |
| Column name | 컬럼명을 표시합니다. |
| DataType | 데이터 유형을 표시합니다. |
Numeric Type
Numeric 컬럼을 선택한 경우 다음의 정보를 추가로 제공합니다.
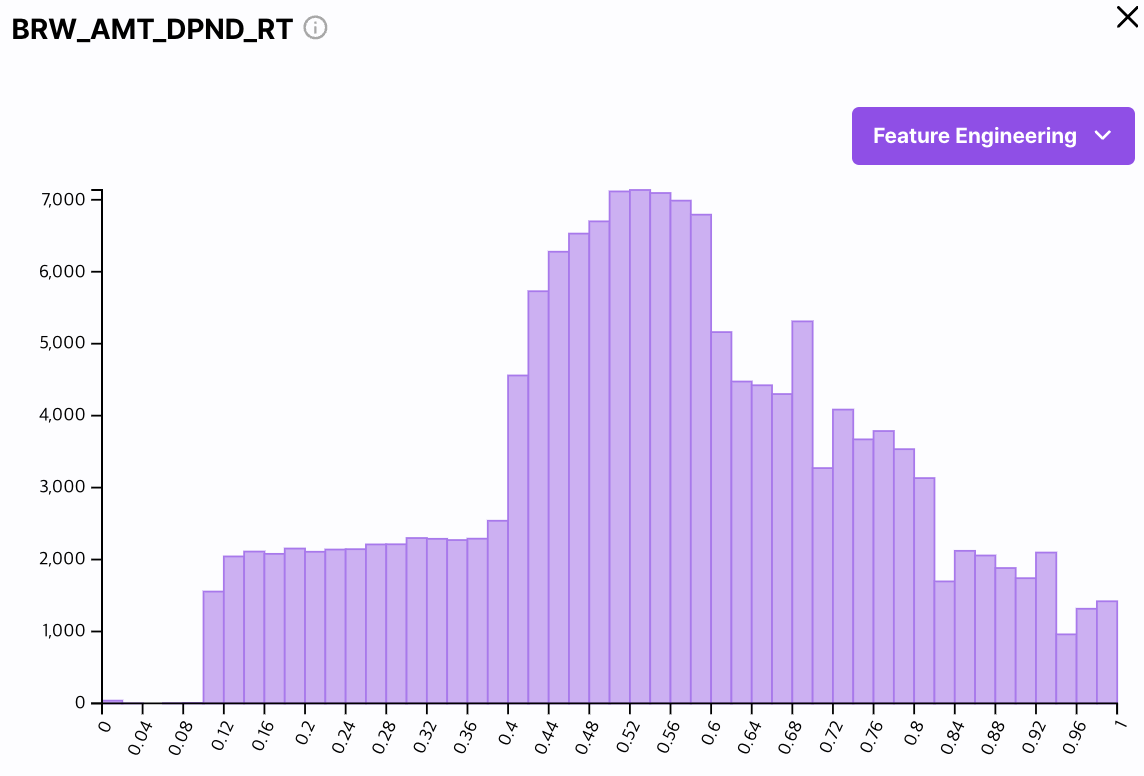
- 히스토그램 차트
선택한 컬럼의 히스토그램 차트를 표시합니다.
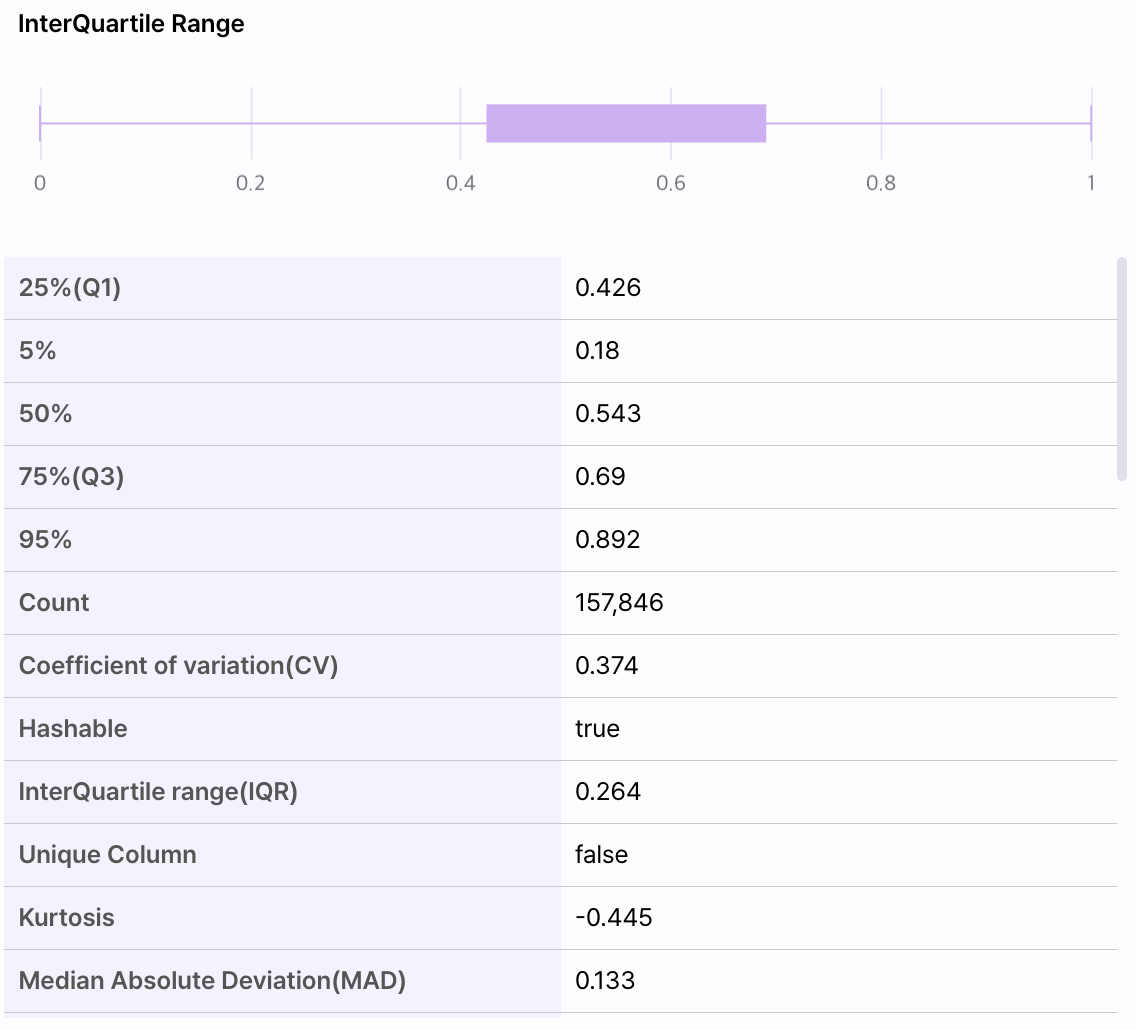
히스토그램은 도수분포표를 그래프로 나타낸 것으로 가로축이 값, 세로축이 빈도를 표시합니다. - IQR 박스 플롯
선택한 컬럼의 IQR 박스 플롯을 표시합니다.
IQR은 Intrer Quatile Range의 약자로 데이터의 사분편차를 표시합니다.
데이터의 최소부터 최댓값까지의 구간을 4등분 하여 분포와 분산된 정보를 확인할 수 있습니다.
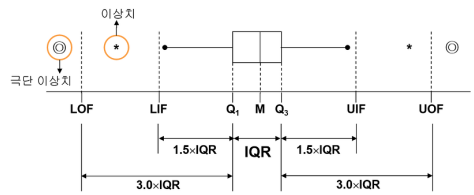
그림과 같이 데이터의 분포를 통해 이상치의 범위를 확인합니다.
데이터 분석을 통해 해당 범위를 포함시킬지 결정할 수 있는 지표로 사용할 수 있습니다.
Columns
특징 분석 화면 중 Columns 탭은 다음의 정보를 표시합니다.
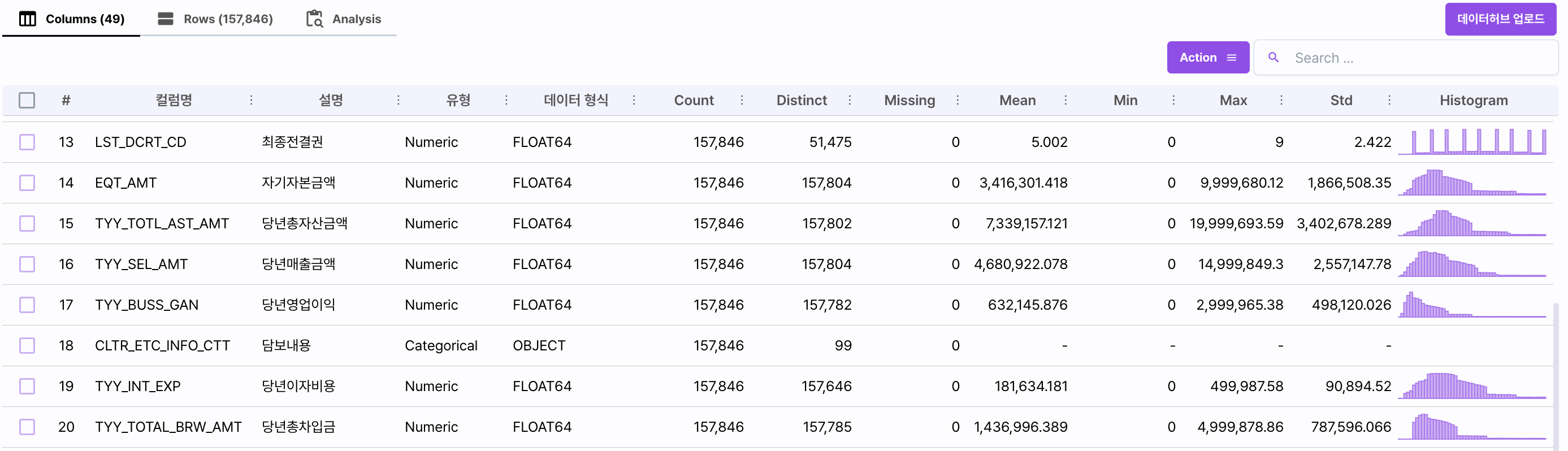
| 필드명 | 설명 |
|---|---|
| 컬럼명 | 해당 컬럼의 명칭입니다. |
| 설명 | 컬럼명에 대한 별칭입니다. |
| 유형 | 해당 컬럼의 분류 타입입니다. Categorical / Numeric 으로 구성되어 있습니다. |
| 데이터 형식 | 데이터의 실제 타입 입니다. Object, String, Int, Float, Boolean과 같은 기본 타입으로 구성되어 있습니다. |
| Count | 해당 컬럼의 로우 수를 표시합니다. |
| Distinct | 중복되지 않은 로우의 수를 표시합니다. |
| Missing | 누락된 값이 포함된 로우의 수를 표시합니다. |
| Mean | 데이터의 평균 값을 표시합니다. Numerical한 컬럼에만 표시됩니다. |
| Max | 데이터의 최대 값을 표시합니다. Numerical한 컬럼에만 표시됩니다. |
| STD | 데이터의 표준편차 값을 표시합니다. Numerical한 컬럼에만 표시됩니다. |
| Histogram | 데이터의 빈도 그래프를 표시합니다. Numerical한 컬럼에만 표시됩니다. |
Rows
특징 분석 화면 중 Rows 탭은 전체 데이터의 컬럼, 로우별 데이터를 확인할 수 있습니다.
앞서 통계로 확인했던 컬럼별 구성과 데이터의 분포를 실제 데이터를 통해 파악할 수 있으며 누락 데이터, 데이터 유형 변환을 지원합니다.
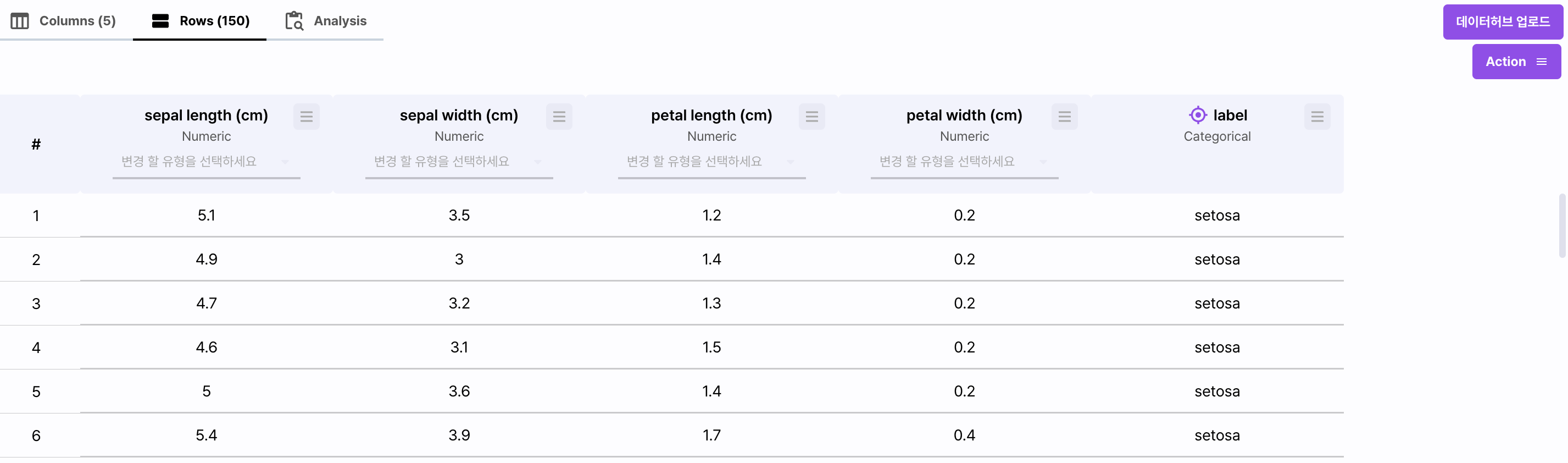
인공지능 모델이 학습하는 환경에서 데이터는 정수와 실수 형태로 표현됩니다.
Categorical 데이터 역시 [사과: 0, 바나나: 1, 배: 2]와 같이 자동으로 인코딩 됩니다.
데이터 유형 변환은 이처럼 모델이 학습하기 위한 형태로 변형하기 위해 잘못 등록된 데이터 유형을 변환할 수 있습니다.
현재 Numeric, DateTime, Categorical로의 변환을 지원합니다.
Analysis
특징 분석 화면 중 Analysis 화면은 컬럼을 선택해 시각화 자료를 통해 데이터를 분석할 수 있도록 지원합니다.

Chart
Analysis 탭에서 [컬럼 선택] 버튼을 선택하면 수집한 데이터로 분석 가능한 차트 정보를 선택할 수 있습니다.
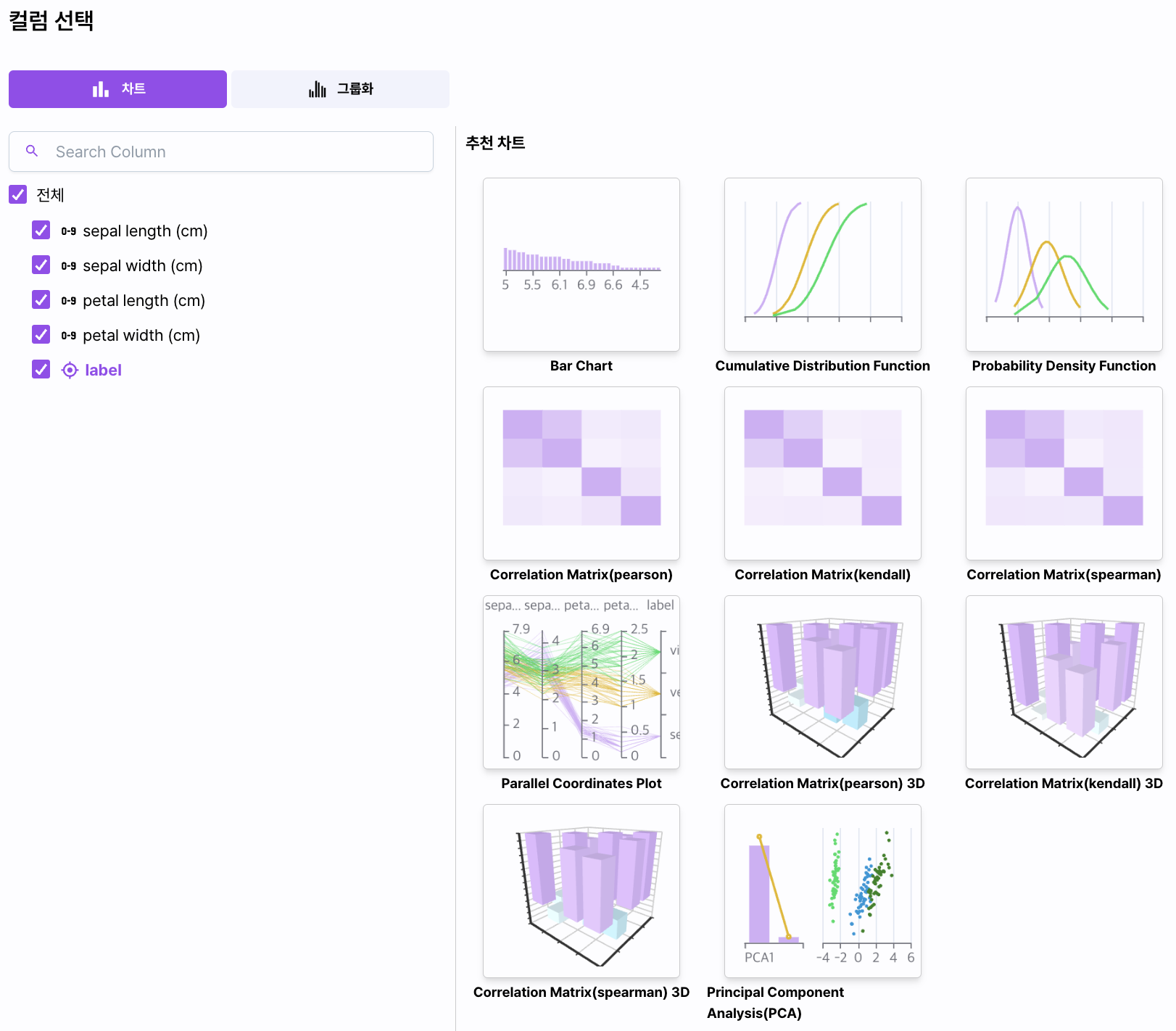
왼쪽에는 수집한 데이터의 컬럼 타입과 컬럼 이름이 표시됩니다.
- A-Z: Categorical 데이터를 의미합니다.
- 0-9: Numeric 데이터를 의미합니다.
왼쪽 열의 컬럼을 선택하면 해당 컬럼으로 분석 가능한 차트들을 자동으로 추천합니다.
Numeric 데이터만을 선택할 때, Categorical 데이터만을 선택할 때, Numeric과 Categorical 데이터를 함께 선택할 때,
Target 컬럼을 포함할 때 등 선택한 케이스에 따라 차트를 자동으로 추천합니다.
Chart 종류
컬럼의 조합을 통해 다양한 차트로 분석 기능을 제공합니다.
- Mosaic plot
2, 3가지 컬럼의 교차 표를 시각화한 자료입니다.
컬럼 내에 존재하는 값을 직사각형으로 표현하여 직사각형의 크기와 색상을 통해 빈도를 직관적으로 확인할 수 있습니다.
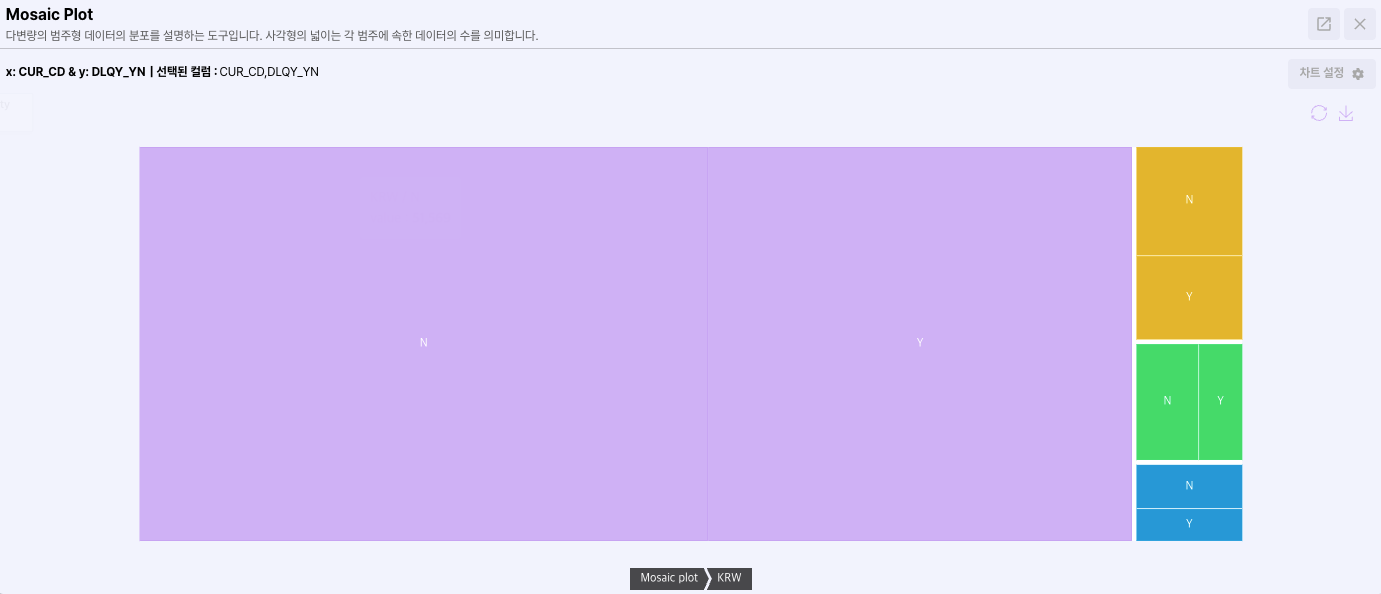
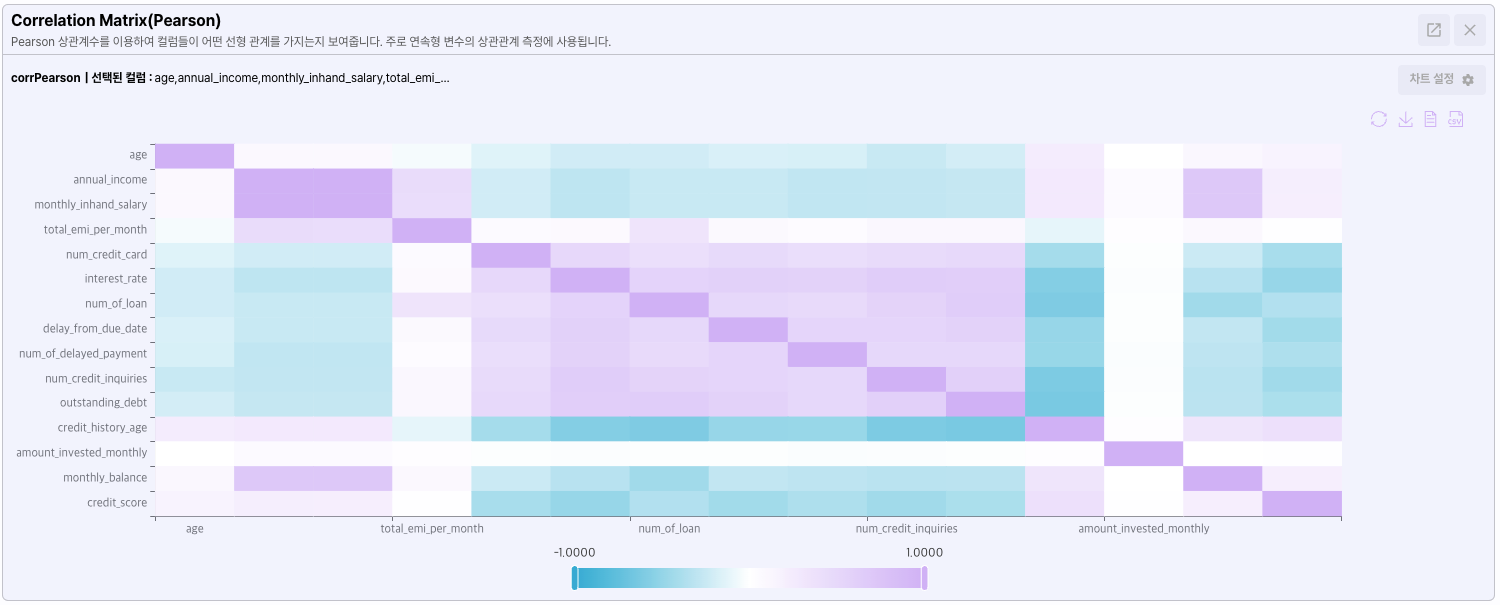
- Correlation matrix
변수들 간의 상관관계를 표시하며, Pearson/Kendal/Spearman 상관계수를 제공합니다.
Correlation matrix를 이용하면 x축과 y축의 변수가 어떤 관계가 있는지 한눈에 알아볼 수 있습니다.
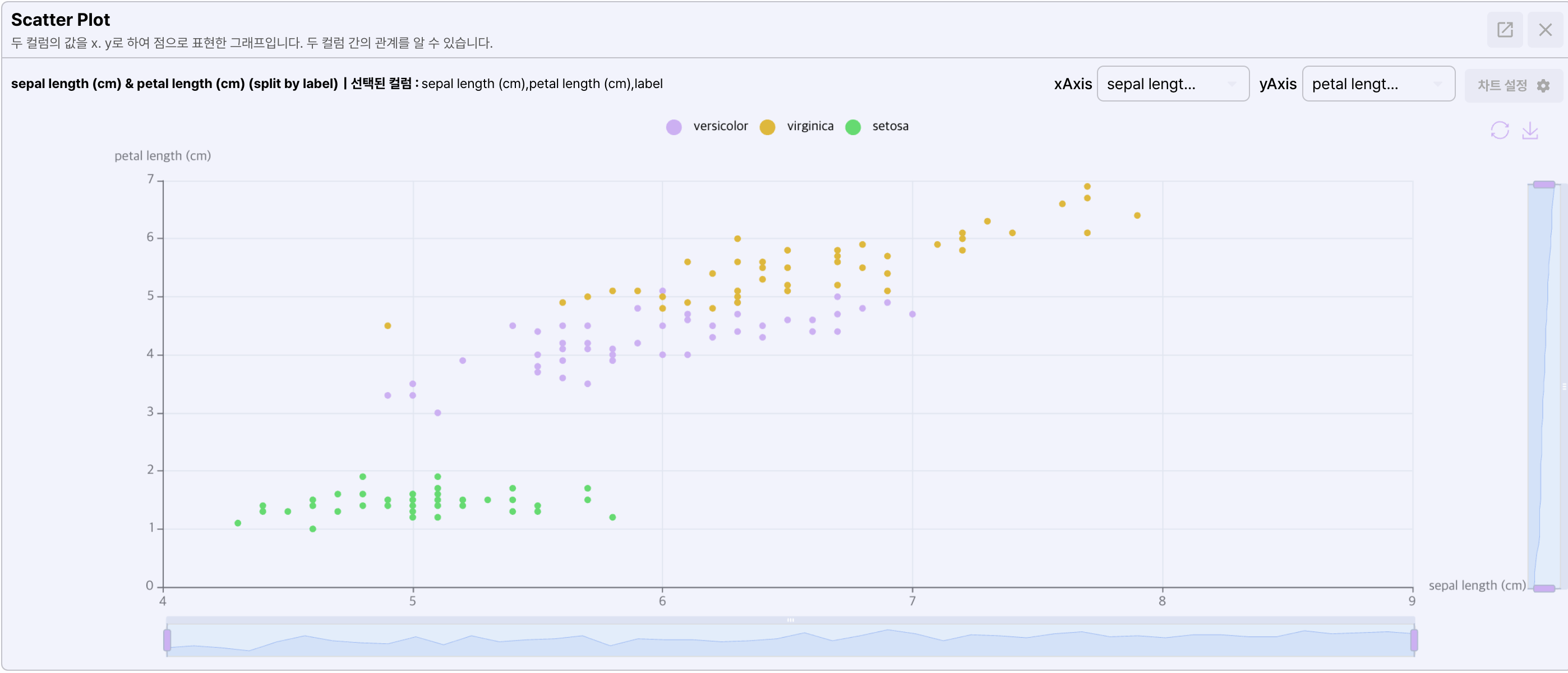
- Scatter plot
두 컬럼의 값을 2차원 좌표 위에 그려 두 변수의 분포와 관계를 표시합니다.
분포가 모여있는 데이터의 추이와 관계를 파악할 때 사용합니다.
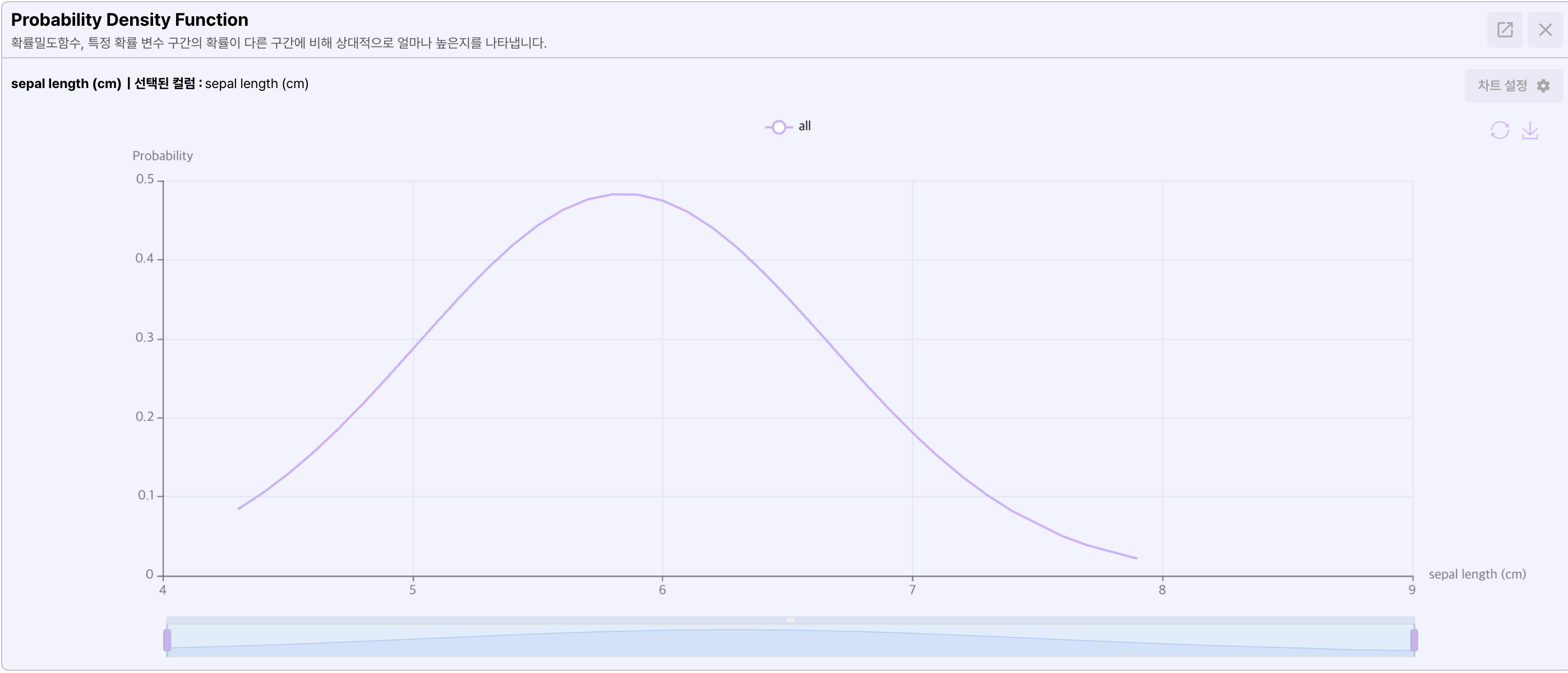
- Probability density function
확률의 분포를 나타냅니다. 확률이 흩어져 있는것을 확률 분포라고 하며 이 확률분포를 함수로 표현한 것이 확률 밀도 함수입니다.
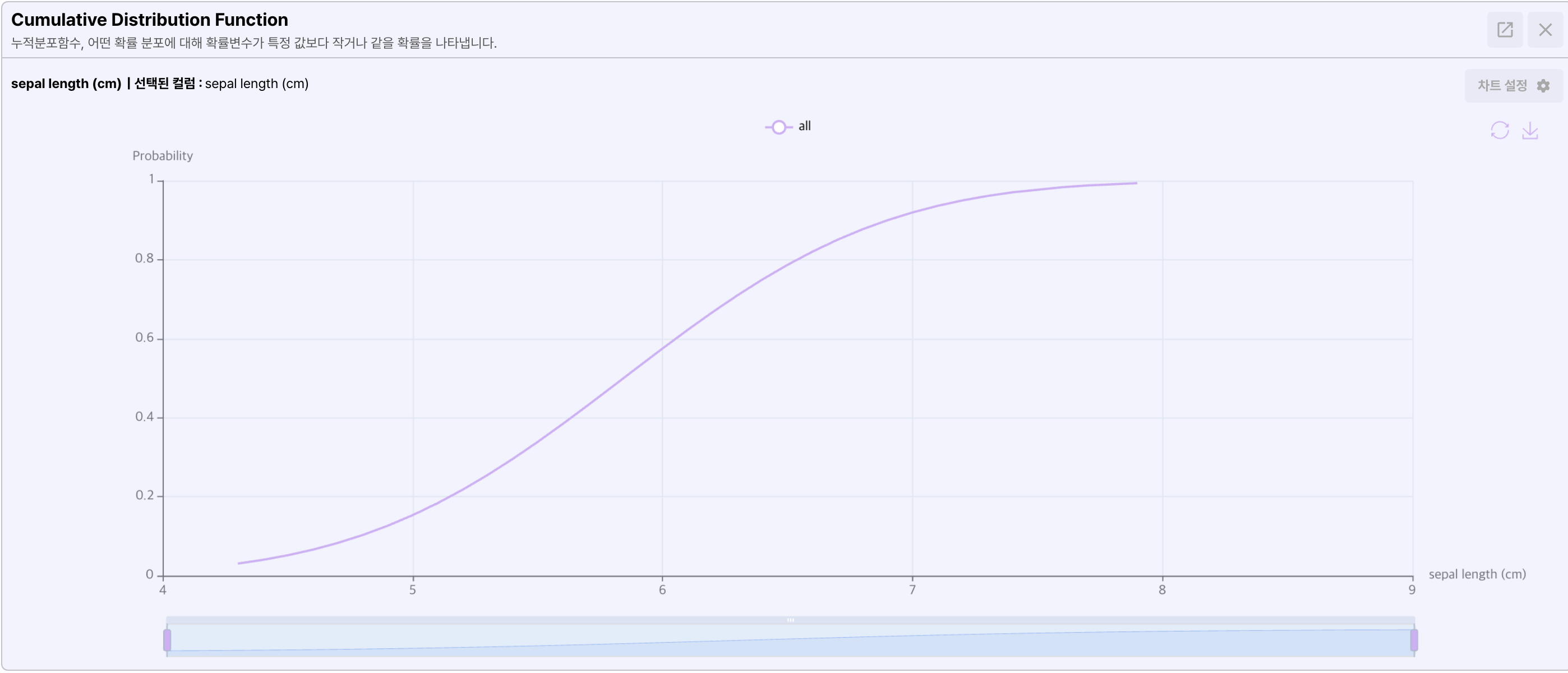
- Cumulative distribution function
누적 분포 함수는 확률 변수의 누적된 정보를 표시합니다.
- Principal Component Analysis(PCA)
고차원의 데이터를 2차원으로 축소하여 분석할 때 사용합니다.
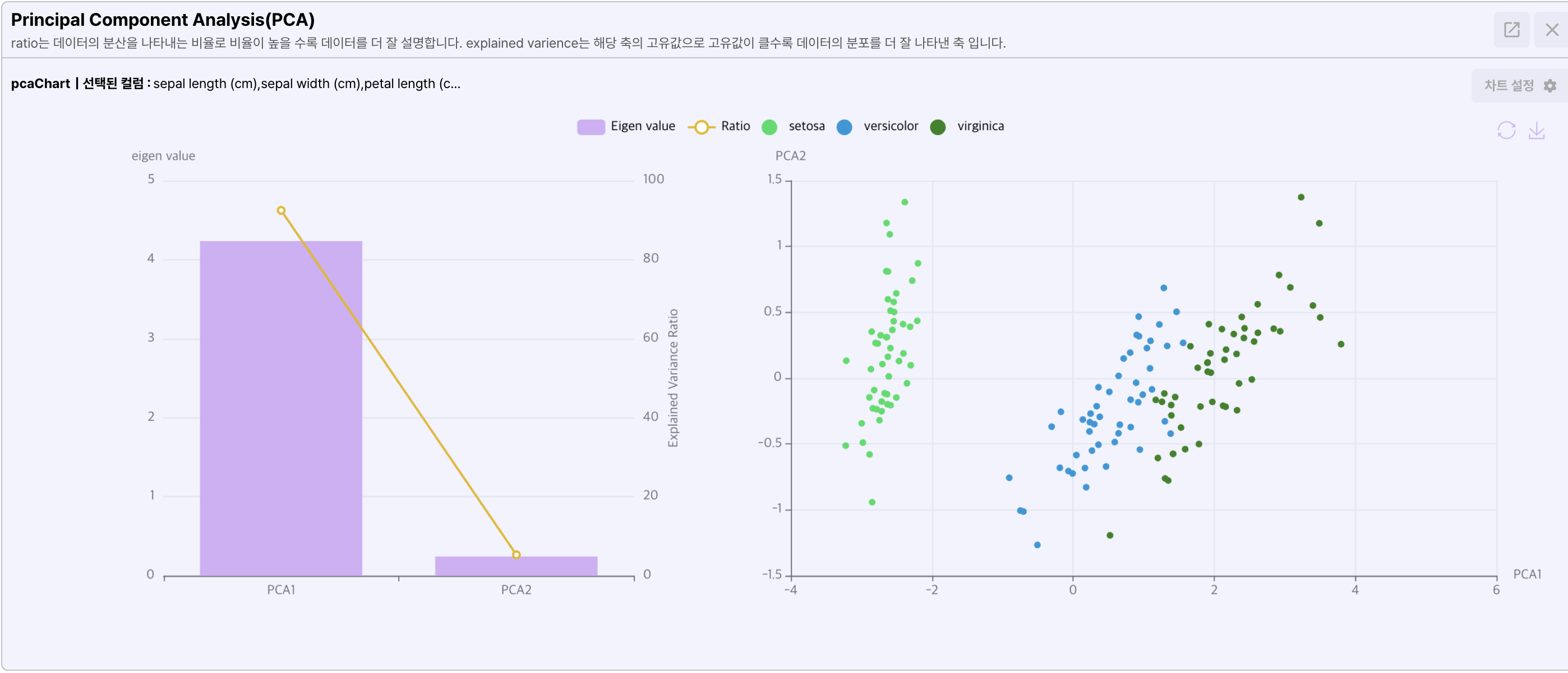
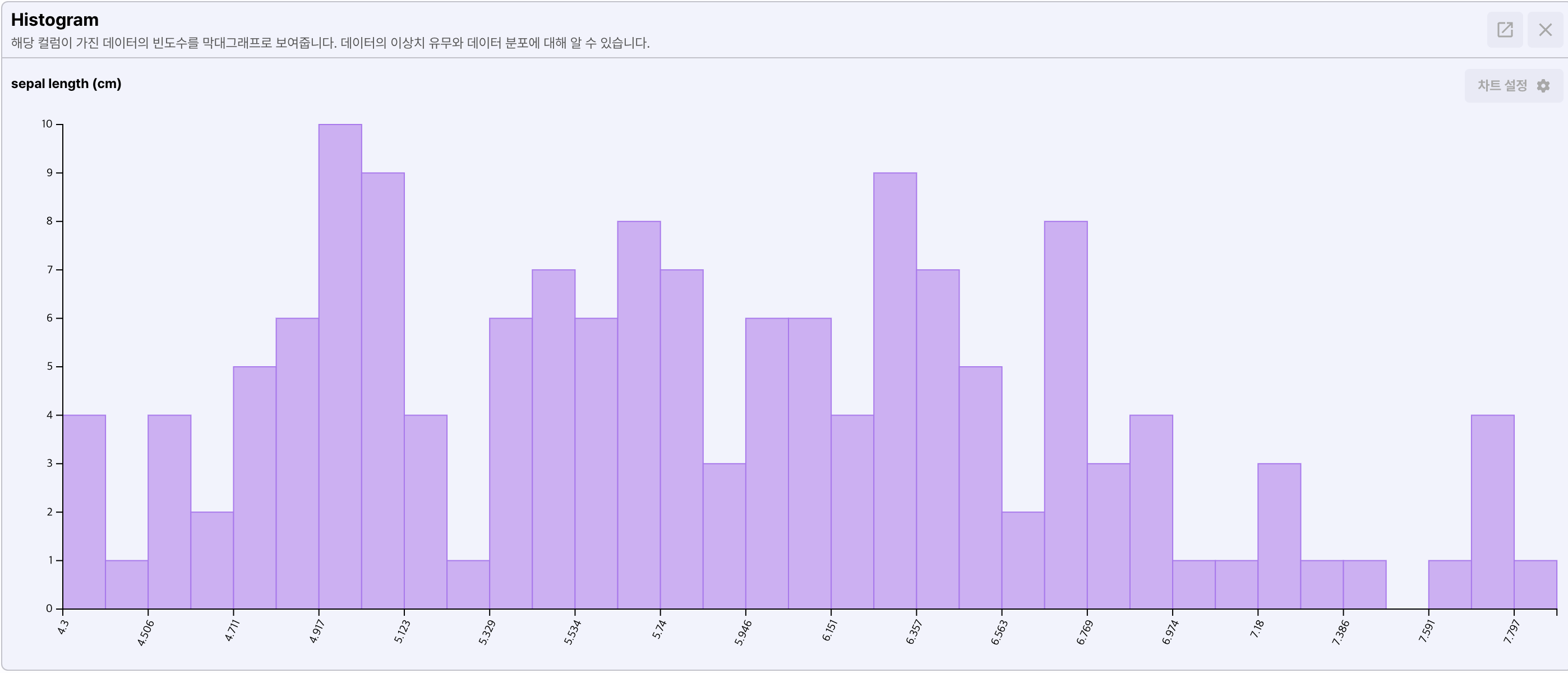
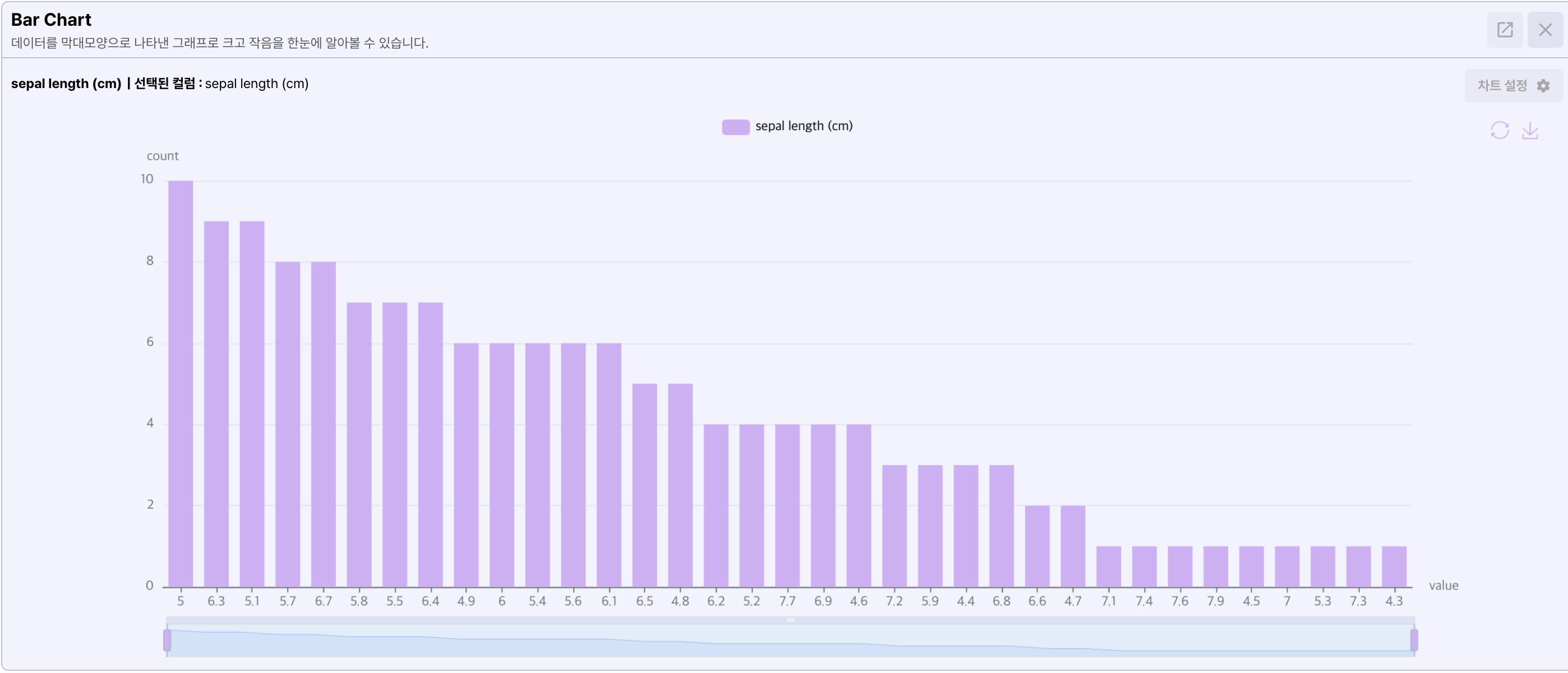
- Histogram
히스토그램은 선택한 컬럼의 빈도를 표시합니다.
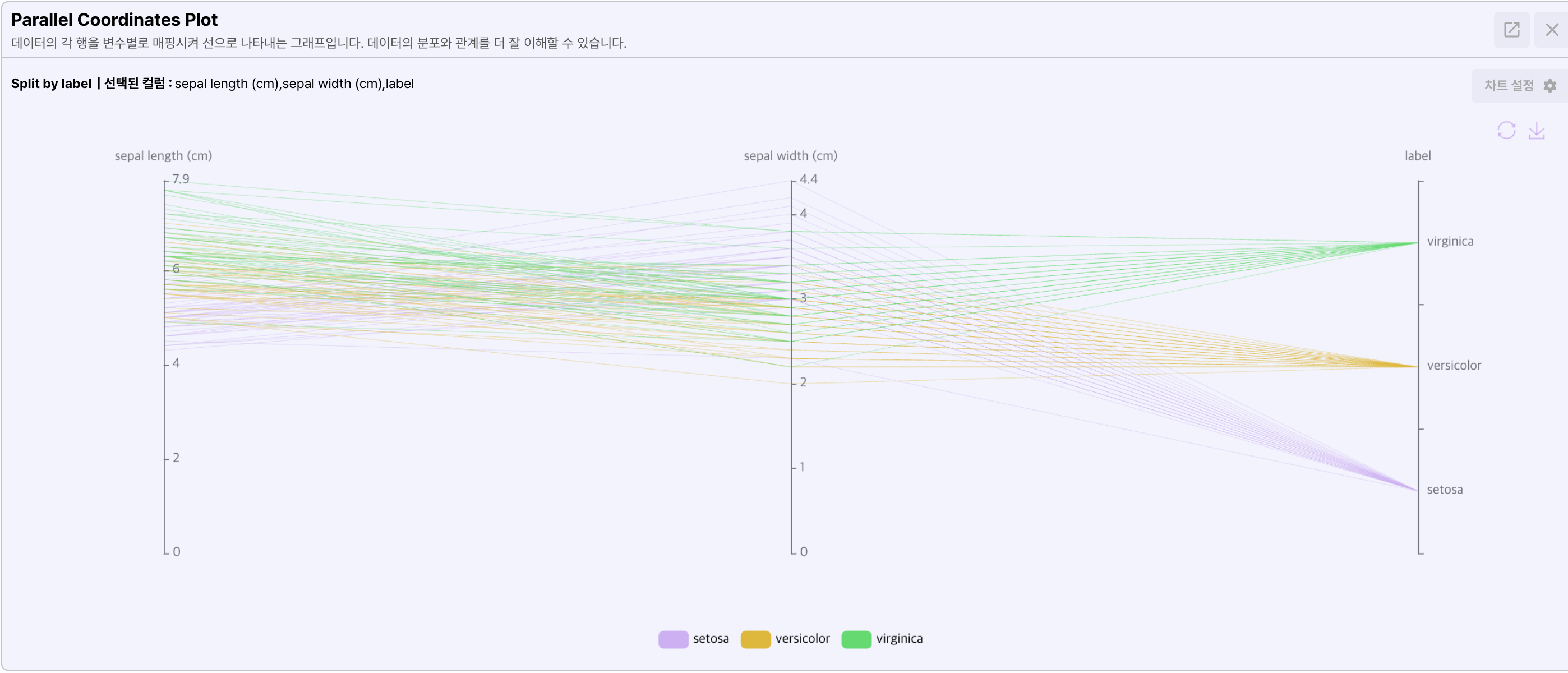
- Parallel coordinates plot
평행좌표는 데이터의 각 컬럼을 변수별로 선으로 매핑시켜 나타낸 그래프입니다.
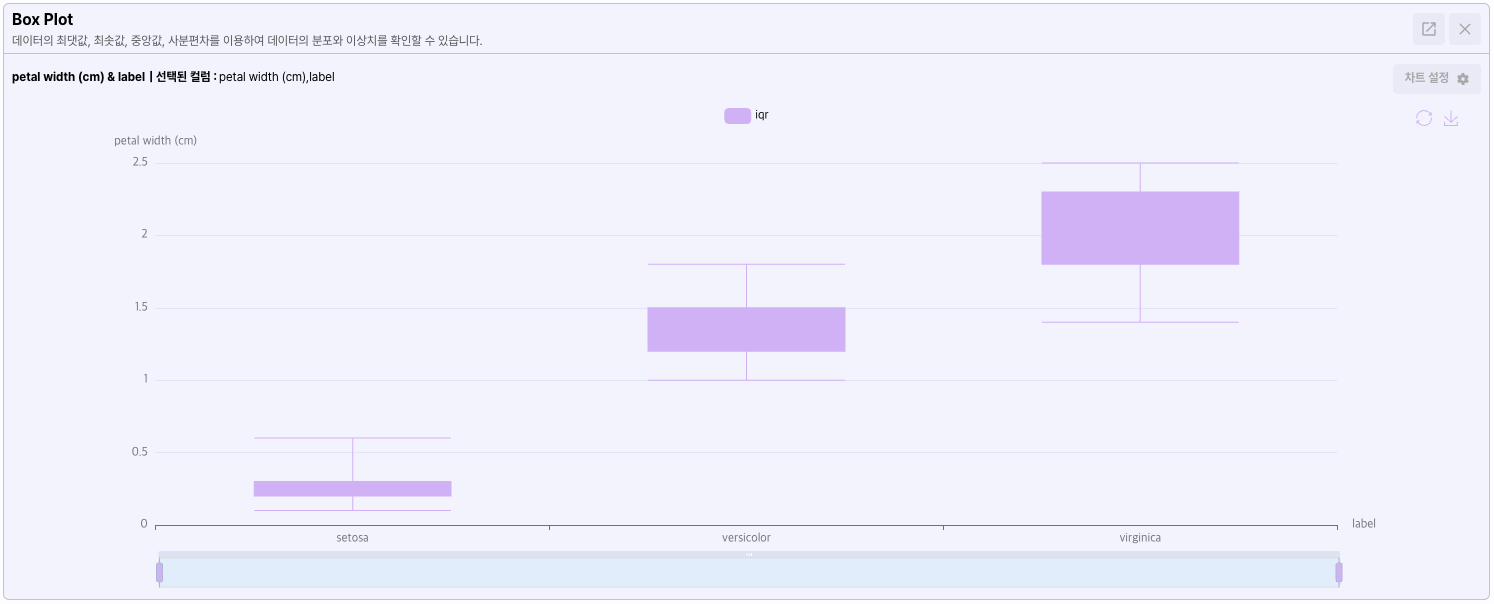
- Box plot
카테고리 데이터와 뉴메릭 데이터를 선택한 경우 카테고리 변수에 대한 Numeric 데이터의 분포를 나타냅니다.
- 3D Chart
Bar, Line 형태로 출력 가능한 데이터를 3차원 좌표에서 분석할 수 있는 3D 차트를 제공합니다.
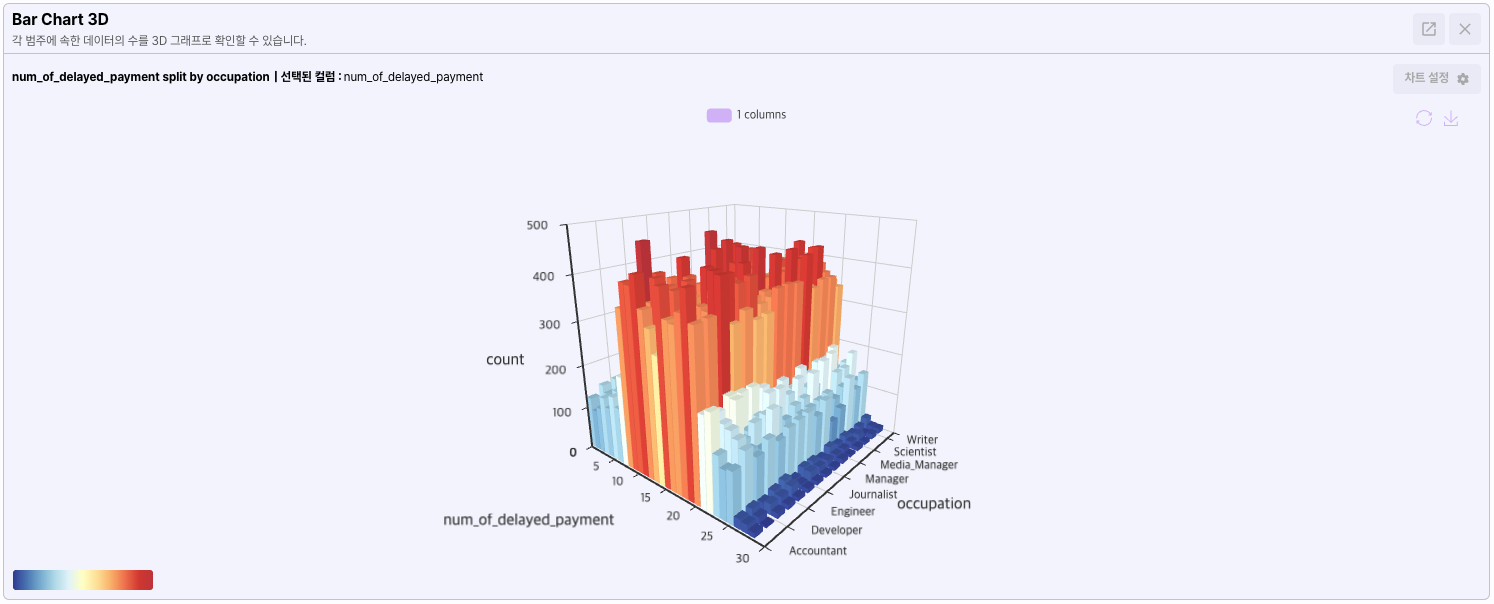
- Bar Chart
수직 막대(bar)로 표현하는 그래프입니다. 각 막대의 길이 또는 높이는 데이터 값에 비례하여 나타나므로 비교 분석에 사용합니다.
GroupBy Aggregation
컬럼 선택 화면에서 그룹화 탭을 선택하면 그룹화 분석이 가능합니다.
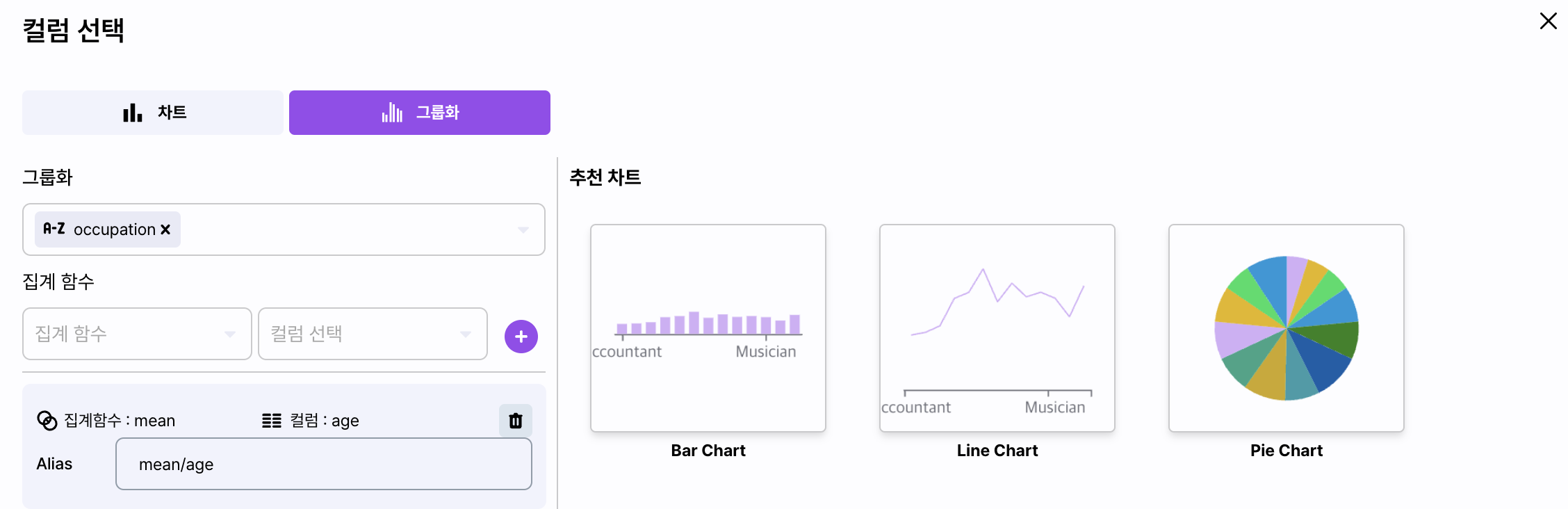
화면 왼편은 그룹화 대상 컬럼과 집계 함수를 설정할 수 있습니다.
- 그룹화: 그룹 대상이 되는 컬럼을 선택합니다. 다중 선택시 복수의 차트가 구성됩니다.
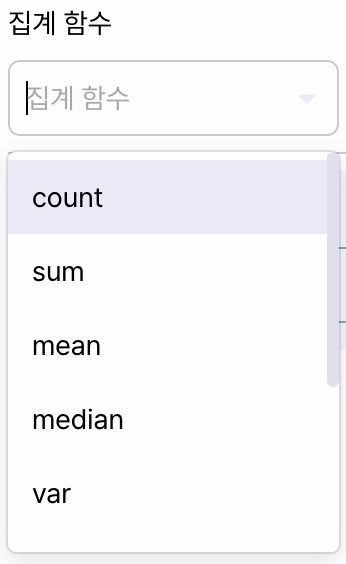
- 집계 함수: 대상 컬럼의 그룹별 데이터를 집계하는 방식을 선택합니다.
그룹화 함수는 COUNT(개수), SUM(총합), MEAN(평균), MEDIAN(중앙값), VAR(분산)을 제공합니다. - 컬럼 선택: 그룹화 대상 컬럼으로 집계될 컬럼을 선택합니다.
화면의 오른편은 집계 함수로 구성할 수 있는 차트 정보를 표시합니다.
차트는 앞서 소개된 것과 같이 Bar Chart, Line Chart, Pie Chart 그리고 Box Plot이 제공됩니다.
Automation
Tabular-ML 서비스는 데이터 처리를 위한 자동화 기능을 제공합니다.
자동화 기능은 전체 적용 여부, 데이터셋의 Purpose, 선택한 컬럼에 따라 다양한 선택지를 제공합니다.
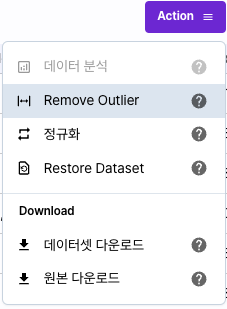
특징 분석 창의 오른쪽 상단의 [Action] 버튼을 클릭하면 데이터셋에 전체 적용 가능한 처리할 수 있는 자동화 기능을 제공합니다.
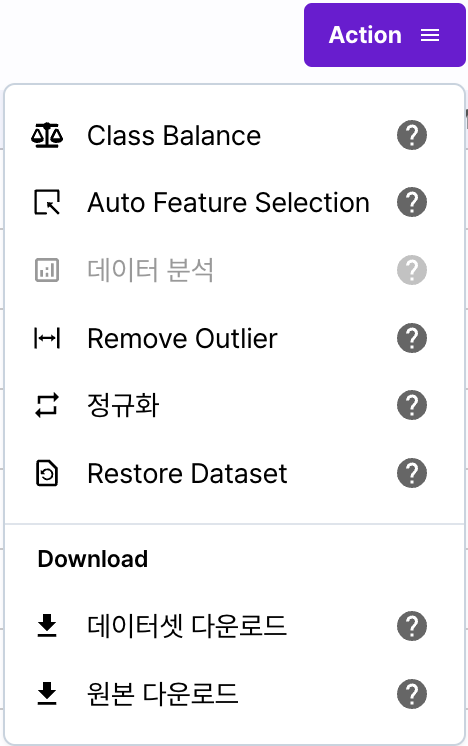
특징 분석 화면의 한 컬럼 위에 마우스를 올리면 선택한 컬럼에만 자동화 기능을 적용할 수 있습니다.

컬럼 왼쪽의 체크박스를 선택한 후 Feature Engineering를 클릭하면 여러 컬럼에 자동화 기능을 적용할 수 있습니다.
 |  |
|---|
시계열 데이터에서는 선택한 컬럼의 특성에 따라 다양한 자동화를 제공합니다.
시계열 데이터에서 시간 컬럼을 선택한 경우 파생 변수 기능을 제공하며, 시간 컬럼을 제외한 일반 컬럼을 선택한 경우 Lag 컬럼 생성, 차분 컬럼 생성. 타겟 컬럼 변경 기능을 제공합니다.


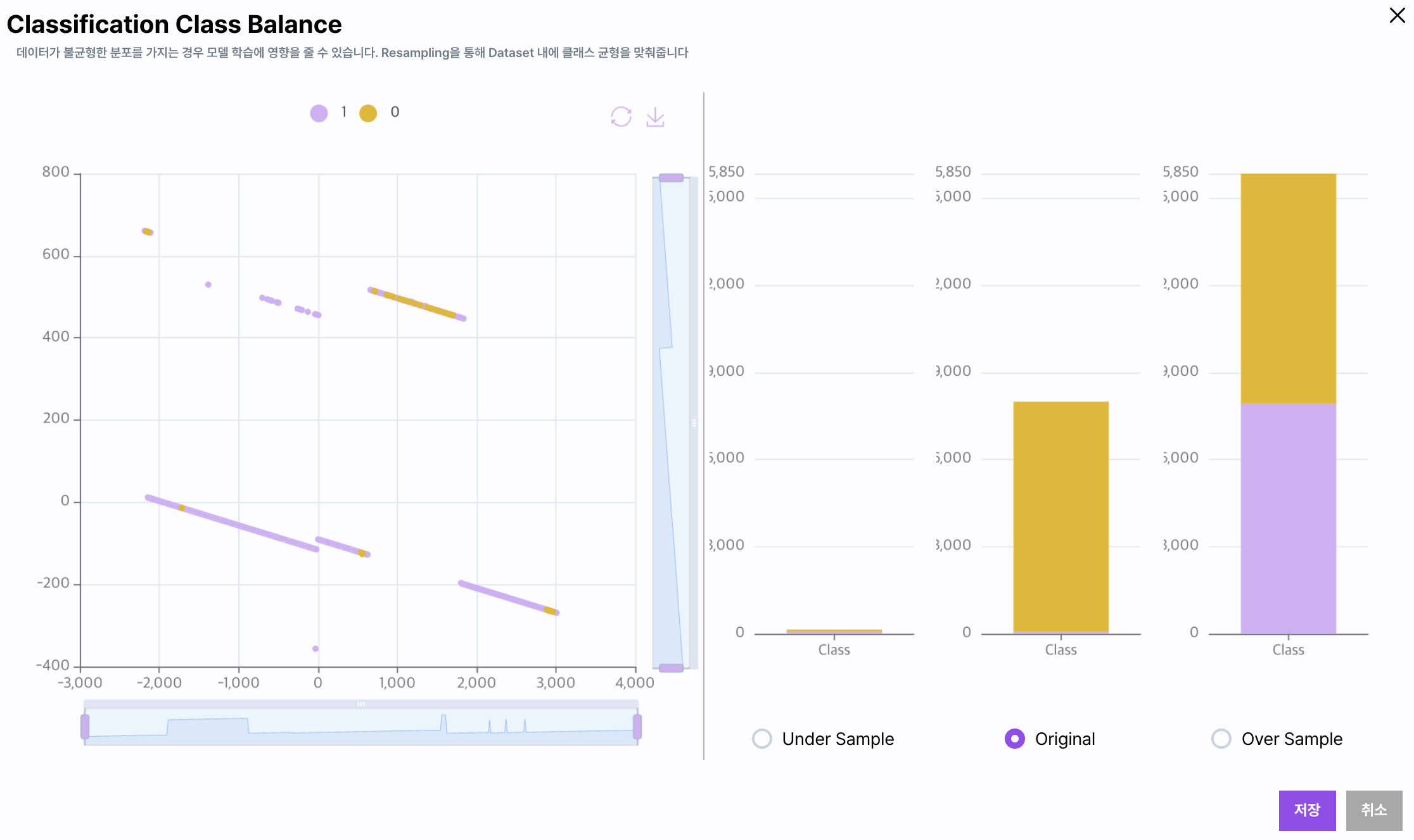
Class Balance
불균형한 클래스 (타겟 컬럼)의 수를 맞추는 작업을 자동으로 진행합니다.
그림과 같이 제일 작은 클래스의 개수로 데이터를 자르는 Under Sample과 제일 수량이 많은 클래스의 숫자와 동일하게 데이터를 증식시키는 Over Sample,
마지막으로 원본 데이터로 변경하는 Original이 있습니다.
원하는 Sample 기법을 선택하고 Save를 클릭하면 잠시 후 데이터가 변경됩니다.
Auto Feature Selection
데이터셋에서 중요한 지표를 인공지능이 스스로 분석해 중요 컬럼만 남기는 전처리 작업을 자동으로 진행합니다.
이 작업은 데이터의 크기에 따라 많은 시간을 필요로 합니다.

Remove Outlier
컬럼들 중 데이터 균형이 맞지 않거나 이상치를 포함하고 있는 데이터에서 자동으로 이상치를 제거해 주는 작업을 진행합니다.
이 작업은 데이터의 크기에 따라 많은 시간을 필요로 할 수 있습니다.

정규화
전체 데이터에 대한 정규화를 진행합니다. 정규화는 데이터를 특정 범위로 변환하여 범위를 일치시키는 작업으로
이상치 처리, 스케일 차이 해결, 모델 수렴 속도의 향상 효과를 기대할 수 있습니다.
정규화를 적용하는 기법으로 정규분포, 최대/최소, IQR, 최대 절댓값 스케일링을 지원합니다.

Restore DataSet
컬럼을 삭제하거나, 아웃라이어 제거와 같은 기능으로 변경된 데이터셋을 처음 업로드한 원상태로 복구하는 기능입니다.

데이터셋 다운로드 / 원본 다운로드
수정한 데이터셋 혹은 원본 데이터를 CSV형태로 직접 다운로드 받을 수 있는 기능을 제공합니다.

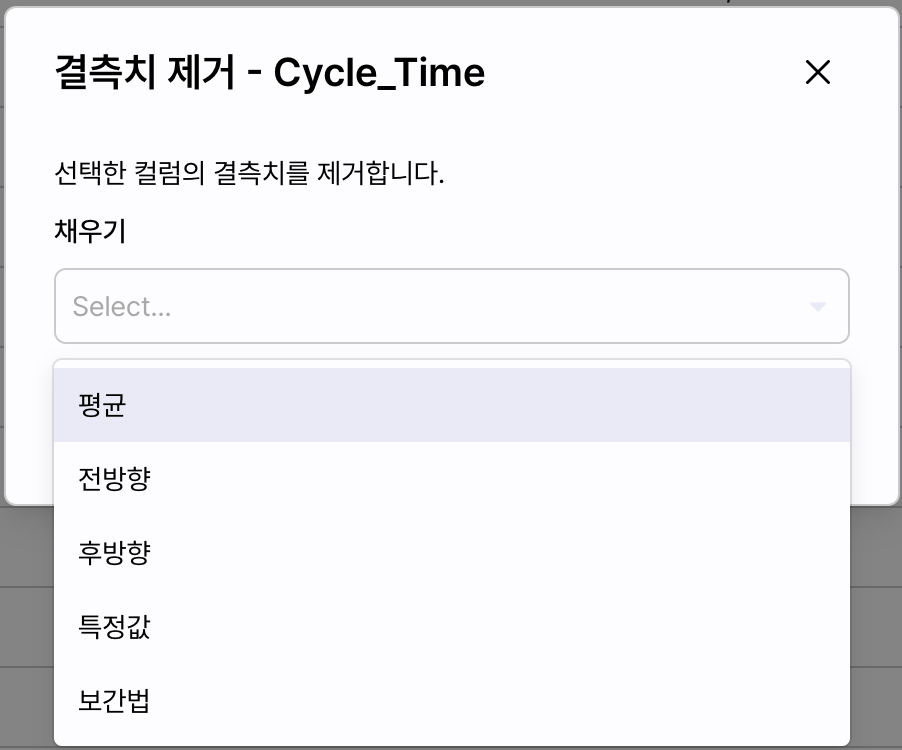
결측치 제거
컬럼에 포함된 결측치를 제거합니다. 결측 데이터의 앞/뒤 데이터에 기반하여 평균, 전/후방향, 보간법 그리고 특정 값으로 결측치를 치환하는 기능을 제공합니다.
파생 변수
날짜 컬럼을 분해하여 새로운 컬럼으로 생성합니다.
예를 들어 [Date:2024-02-12] 라는 컬럼은 [Year:2024], [Month:02], [Day:12]와 같이 분해된 컬럼으로 생성됩니다.
해당 기능은 회귀 모델을 이용해 시계열 학습을 할 때 사용됩니다.

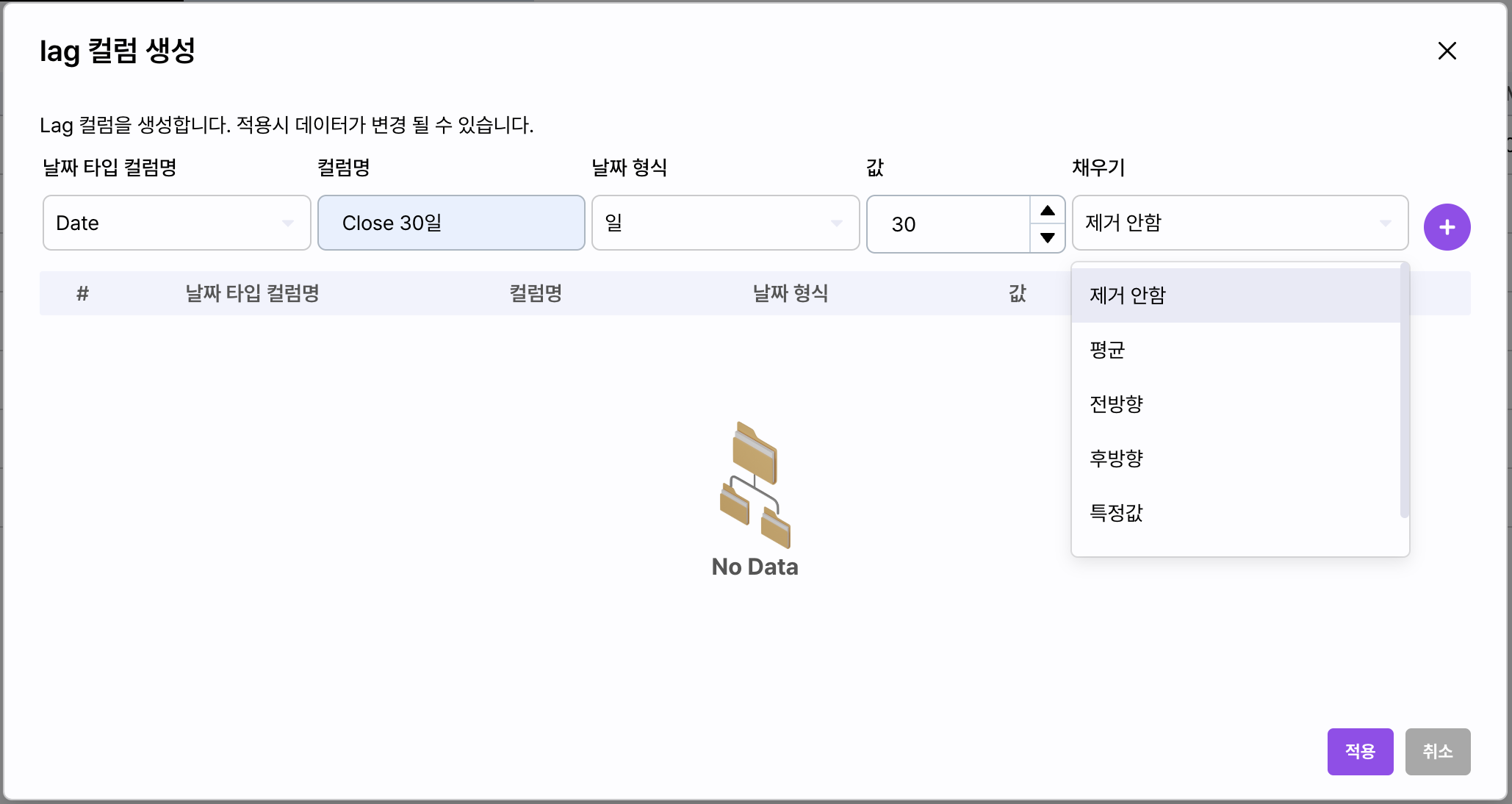
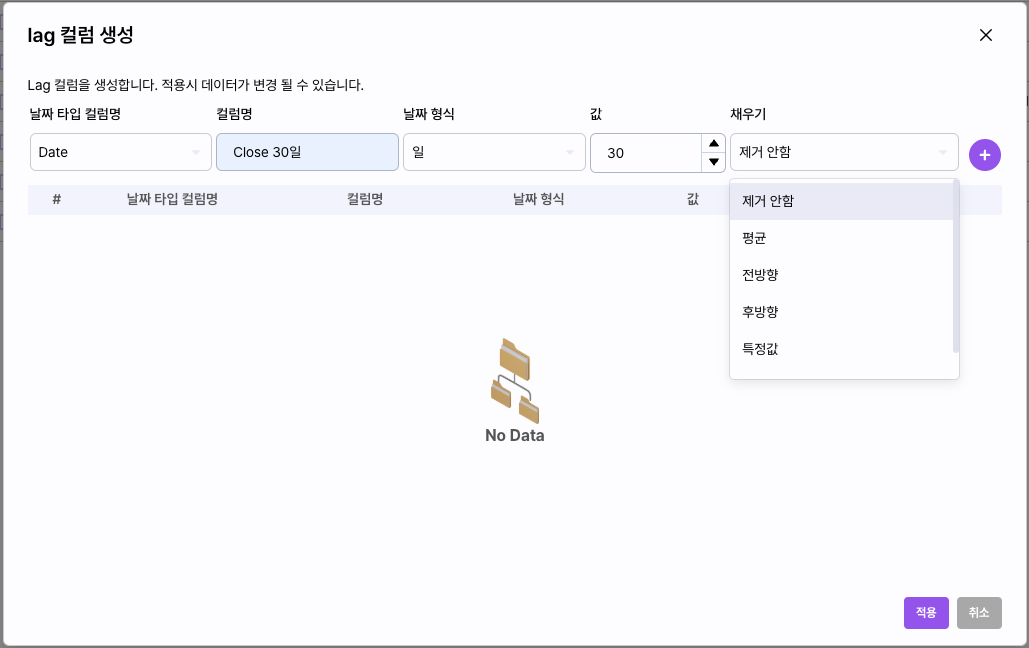
Lag 컬럼
선택한 컬럼의 과거 기준 데이터를 컬럼화합니다.
시계열 데이터에서 주기성을 포함하는 컬럼을 생성하기 위해 사용합니다.
이 작업은 데이터의 크기에 따라 많은 시간을 필요로 합니다.
- 컬럼명: 신규로 생성되는 컬럼의 명칭을 입력합니다.
- 날짜 형식: 주기의 기준이 되는 단위를 선택합니다. 원본 데이터 형태에 따라 년, 월, 일, 시 분 등을 제공합니다.
- 값: 주기의 반복 값을 입력합니다.
- 채우기: 생성된 첫 주기와 현재 데이터 사이의 누락되는 값을 채우는 방식을 결정합니다.
차분컬럼
선택한 데이터의 차분 컬럼을 생성합니다.
차분은 시계열 데이터의 정상성을 나타낼 수 있도록 연속된 데이터 간의 차이를 계산하여 적용합니다.
이 작업은 데이터의 크기에 따라 많은 시간을 필요로 합니다.

데이터 분석
데이터를 변경한 후 경고 메시지의 데이터 분석 버튼 또는 Action의 데이터 분석 버튼을 클릭하면 기술 통계 자료가 업데이트됩니다.

